Python DataFrameの行、列の削除

- DataFrameの行もしくは列の削除方法
- 重複行、重複列の削除方法
- NaN、Noneなどがある行もしくは列の削除方法
(本記事のコードを作成した開発環境はGoogle Colaboratory Python 3.7.13 となります。)
Excel作業の中で任意の行(列)の削除は必要不可欠だと思います。PythonのData Frameで行(列)の削除はdrop系のメソッドを使います。どのメソッドを使うかや、引数設定の方法によってExcelよりも早く正確に複数の行(列)を削除することも可能になると思います。
表の処理を行うには必須のメソッドだと思いますので、本記事で使い方を覚えていただければ幸いです。
紹介するメソッド
- dropメソッド : 複数行(列)を削除
- dropnaメソッド : NaNのセルがある行(列)を削除
- drop_duplicatesメソッド : 重複列(列)の削除
これらメソッドを使えれば大抵のDataFrameにおける行もしくは列の削除ができるようになります。
- dropメソッドの使い方
- dropnaメソッドの使い方
- drop_duplicatesメソッドの使い方
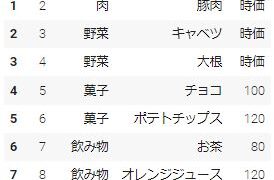
元データとなるexcelファイルを下記に用意しました。ファイル内のSheet1(dfとする)とSheet2(fd2とする)のデータを使っていきます。
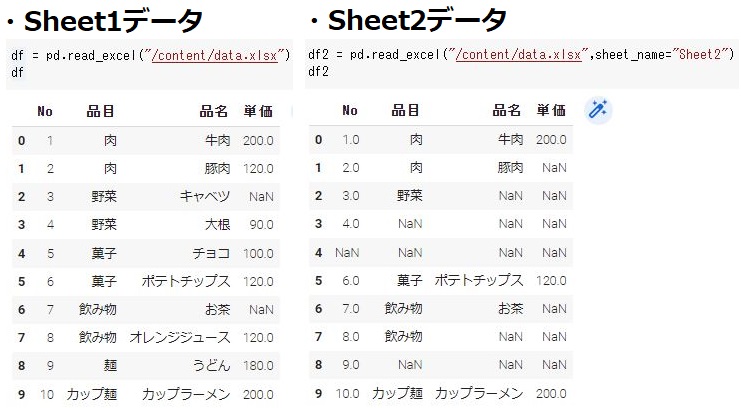
excelファイルの読み込み方は別記事(PythonにExcelやCSVファイルを読込む方法)にて紹介しています。
dropメソッド
通常の行(列)の削除に使用します。drop系メソッドで一番ノーマルで、一番使用頻度の多いメソッドです。リストを使って削除する行(列)名を指定することで、複数行(列)を同時に削除することができます。このとき、行(列)番号ではなく行(列)名で指定したければなりません。番号で指定しようとするとエラーが発生します。
・dropメソッドの引数
| 引数名 | デフォルト値 | 詳細 |
| labels | None | 削除したい行(列)名を指定(複数ならリスト) |
| axis | 0(行方向) | 1で列方向 |
| index | None | 行名の文字列(複数行ならリスト) |
| columns | None | 列名の文字列(複数列ならリスト) |
| level | None | マルチインデックスのDataFrameに対して使う |
| inplace | False | TrueでもとのDataFrameを上書きして変更する |
| errors | raise | ‘ignore’にすると存在しな行(列)名を渡しても自動的にスルーしてくれる |
・行(列)の指定方法(labels、axis、index、columns)
削除する行(列)を指定するには2通りの方法があります。
- ・「labels」で削除したい行(列)名を選択し、「axis」で削除方向を指定してする方法
- ・行なら「index」、列なら「columns」を使って削除する行(列)名を指定する方法
indexとcolumnsは同時に設定できますが、index、columnsとlabelsは同時に設定できません。設定すると「Cannot specify both ‘labels’ and ‘index’/’columns’」というエラーが出てきます。
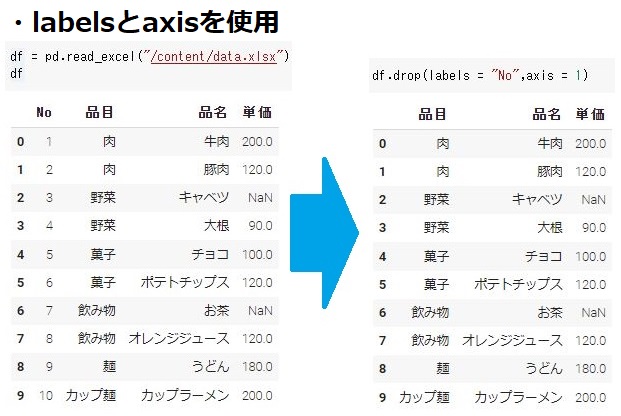
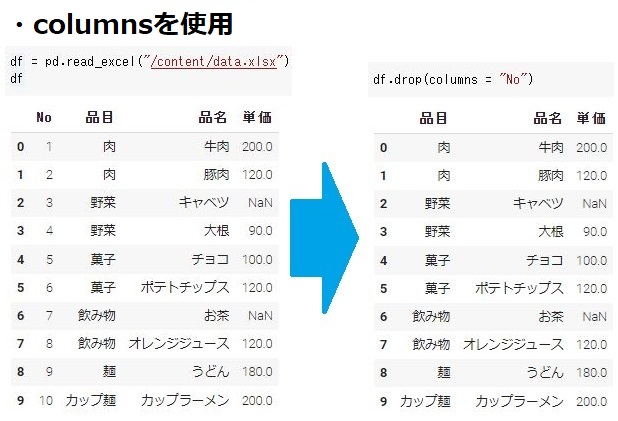
Data Frame「df」から「No」の列を削除してみたいと思います。
|
1 2 3 4 5 6 |
#labelsとaxisを使用して"No"の行を削除 df.drop(labels = "No",axis = 1) #columnssを使用して"No"の行を削除 df.drop(columns = "No") |
・マルチインデックスに対する設定(level)
マルチインデックス(行名が2つあるData Franeのこと)に対する設定になります。別記事にて紹介予定
・DataFrame上書き変更に関する設定(inplace)
「Data Frame名.drop(引数)」で記載すると削除されたData Frameが表示されますが、上書きで更新しているわけではないので、再度Data Frameを表示させると削除されていない状態になっています。引数「inplace = True」にすることによって上書き更新されるようになります。「Data Frame名 = Data Frame名.drop(引数)」でdropで即除したData Frameを新しいData Frameに代入するのと同じ結果を得られます。
・存在しない行(列)名が出た際の設定(errors)
dropでは削除する行(列)名を引数に入れますが、入れた行(列)名がData Frameに無い場合、エラーが発生します。「errors = “ignore”」にすることで、存在しない行(列)名が出てきたときにそれをスルーしてくれます。
dropnaメソッド
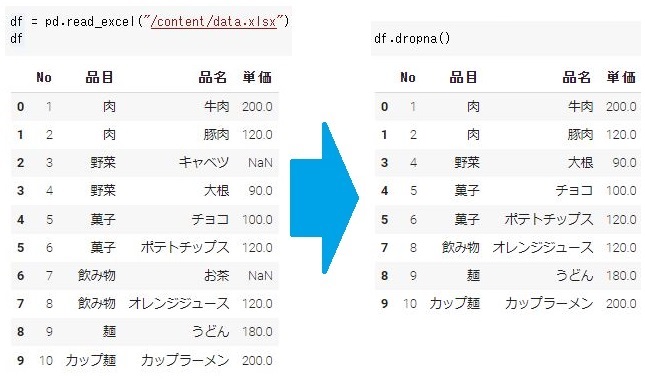
NaN、Noneといった欠損値のある行(列)を削除します。下のData Frameでは2行目と6行目の単価に欠損値があります。そのため、dropnaメソッドを使用すると2行目and6行目が行削除されます。
|
1 2 |
#欠損値のある行の削除 df.dropna() |
・dropnaメソッドの引数
| 引数名 | デフォルト値 | 詳細 |
| axis | 0(行方向) | 1で列方向 |
| how | ‘any’ | anyは少なくとも一つ欠損値がある行(列)を削除 allはすべて欠損値の行(列)を削除する |
| thresh | なし | 整数を渡し、その整数以上の欠損値でないデータ数を持つ行(列)は削除しない |
| subset | なし | 列名をリストで渡し、その列の中から欠損値をのある行を削除 |
| inplace | False | TrueでもとのDataFrameを変更する |
・行方向を消すか列方向を消すかの指定(axis)
欠損値に対して行方向or列方向どちらを消すかを設定します。デフォルトでは行方向が指定されているため、引数を設定しなければ上記のように行番号で2と6が消えます。引数に「axis = 1」を設定すると単価が消えます。
|
1 2 |
#欠損値のある列の削除 df.dropna(axis = 1) |

・欠損値のあり方によって行(列)を削除する(how、thresh)
引数「how」を設定することで行(列)のデータがすべて欠損値だった場合、削除するといった設定ができます。howはデフォルトでは「how = “any”」に設定されているため、1つでも欠損値があれば削除の対象となります。

「how = “all”」のすることですべて欠損値の場合、削除する設定になります。下のData Frameは4行目がすべて「NaN」になっています。そのため、allの設定で4行目のみが削除されます。
|
1 2 |
#すべて欠損値の行を削除 df2.dropna(how = "all") |
引数「how」を使うと「1つでも欠損値 or すべて欠損値」という両極端の設定しかできません。この間の設定をするには引数「thresh」を使います。threshは整数を渡すことで、その整数以上の欠損値でないデータ数を持つ行(列)を削除しない設定ができます。
下のData Frameにdropnaメソッドの引数「thresh = 3」を設定して行削除してみます。すると、要素のあるデータが3個以上ある行を残して他を削除することができます。
|
1 2 |
#要素のあるデータが3個以上ある行を残して他を削除 df2.dropna(thresh = 3) |

・指定した列の中に欠損値がある行を削除(subset)
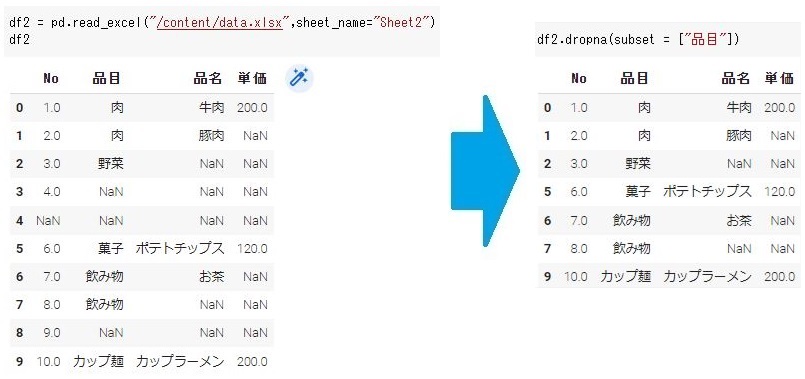
引数「subset」を使うことで列名を指定して、その列中で欠損値となっている行を削除することができます。
下のData Frameにdropnaメソッドの引数「subset = [“品目”]」を設定してしてみます。品目がNaNになっている行を削除できました。(このとき、column名はリストで指定しないとエラーになります。)
|
1 2 |
#品目がNaNになっている行を削除 df2.dropna(subset = ["品目"]) |
drop_duplicatesメソッド
指定した列に同一値のある行を削除するときに使用する。
・drop_duplicatesメソッドの引数
| 引数名 | デフォルト値 | 詳細 |
| subset | 全ての列 | 指定した列で重複した行を削除 |
| keep | first’ | firstは重複行の最初を残す lastは重複行の最後を残す Falseは重複行をすべて削除 |
| ignore_index | False | Trueでindexを0からに変更する |
| inplace | False | TrueでもとのDataFrameを変更する |
・指定した列の中から重複した行を削除(subset)
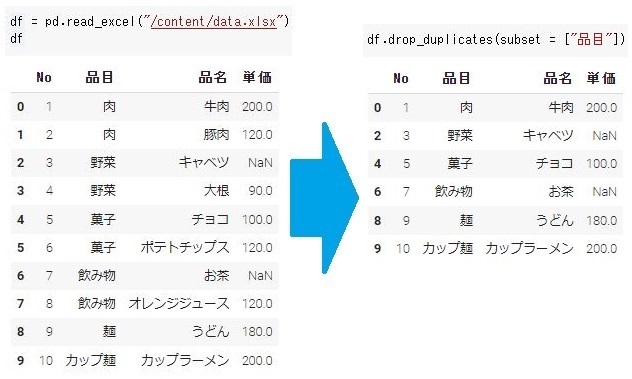
列名を指定し、値が重複している場合その行を削除します。重複している中でどの行を削除するかは次に紹介する引数「keep」で指示出来ます。(デフォルト行番号が若い方が残る)複数の列名に対し手の重複を指示したい場合はリストで指定します。
|
1 2 |
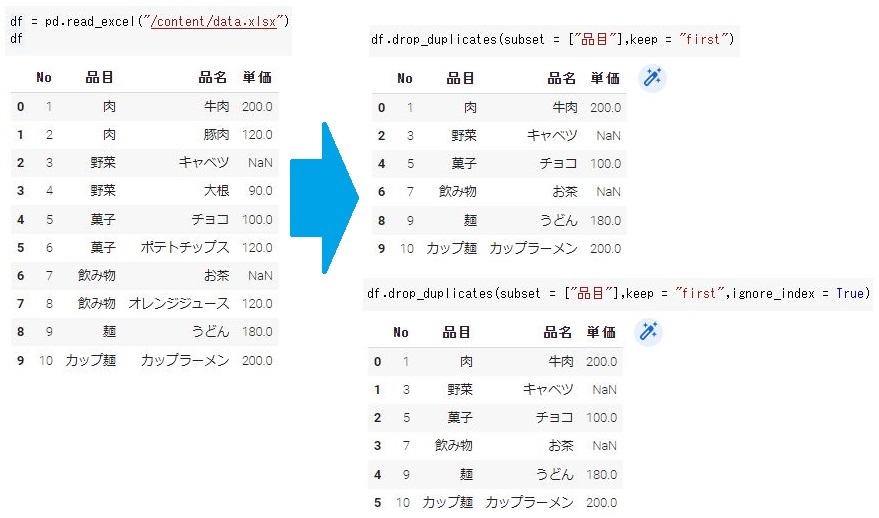
#指定した列の中から重複した行を削除 df.drop_duplicates(subset = ["品目"]) |
・どの行を残すかを選択する(keep)
重複を削除する際に最初の行を残すか、最後のデータを残すか、重複データを全部消すかを選択できます。デフォルトは最初のデータを残す「”first”」が設定されているので、特に指示をしなければ行番号が若い方が残ります。
|
1 2 3 4 5 6 7 8 |
#重複行の最初を残す(first) df.drop_duplicates(subset = ["品目"],keep = "first") #重複行の最後を残す(last) df.drop_duplicates(subset = ["品目"],keep = "last") #重複行をすべて削除(False) df.drop_duplicates(subset = ["品目"],keep = False) |

・行番号を採番しなおす(ignore_index)
行を削除すると削除された行番号がなくなります。「ignore_index = True」にすることにより、行番号を新たに0から採番しなおすことができます。
|
1 2 |
#行番号を採番し直す df.drop_duplicates(subset = ["品目"],keep = "first",ignore_index = True) |