Pythonで機械学習 pycaretの使い方
- Pythonで機械学習を行いたい
- pycaretを使ってみたい方
- 無料で機械学習を行う方法を知りたい
(本記事のコードを作成した開発環境はGoogle Colaboratory Python 3.10.12 となります。)
今回は、機械学習モデルを簡単に作成できるPythonのパッケージ「Pycaret」の使い方について解説していきます。
私自身AIや機械学習といった技術を仕事で生かせないものかと思ってはいましたが、「難しそう」、「お金がかかりそう」といった理由から手が出せずにいました。
今回紹介する「Pycaret」は簡単に機械学習が行え、Pythonが使える環境であれば良いので、無料で使用できる「Jupyter Lab」や「Google Colaboratory」で問題なく動作することができます。
本記事を参考に皆さんも機械学習にチャレンジしていただければ幸いです。
- pycaretでできること
- pycaretを使った数値予測の流れ
- 学習データと予測したいデータ
- pycaretの使用方法
- コードのまとめ
❶pycaretでできること
1.学習データの前処理(setup メソッド)
機械学習に使用する学習データの前処理をsetupメソッドで行えます。前処理では、各columnのデータ型の設定や欠損値の処理など、これから機械学習のトレーニングをさせるのに使用する学習データのクレンジングを行います。
2.複数アルゴリズムの比較(compare modelsメソッド)
pycaretでは複数のアルゴリズムでmodelを作成することができます。compare modelsメソッドでは簡易的ではありますが、pycaret使用できる複数のアルゴリズムを計算することでどのアルゴリズムを使ったmodelが最適なのかを示してくれます。
3.modelの作成
model作成時に使用するメソッドは複数あります。順に処理することでmodelの精度をあげていきます。
・create modelメソッド
引数で指定したアルゴリズムでmodelを作成できます。
・tune modelメソッド
modelのハイパーパラメータを調整します。
・evaluate modelメソッド
引数で指定したmodelに対して、精度を把握するためのグラフや表を表示できます。
・finalize modelメソッド
与えられた全ての学習データを使ってモデルを最終版の作成します。
・save modelメソッド
作成したmodelを保存します。
4.modelの適用
load modelメソッドを使い、作成したmodelを読み込み、predict modelメソッドにて予測を実行します。
➋pycaretを使った数値予測の流れ
下記のpycaretで行うmodel作成とその使用方法の流れを図解します。
❸学習データと予測したいデータ
機械学習を活用するためには
- 学習データ(AIにトレーニングさせるためのデータ)
- 予測したいデータ
の2つのデータが必要です。
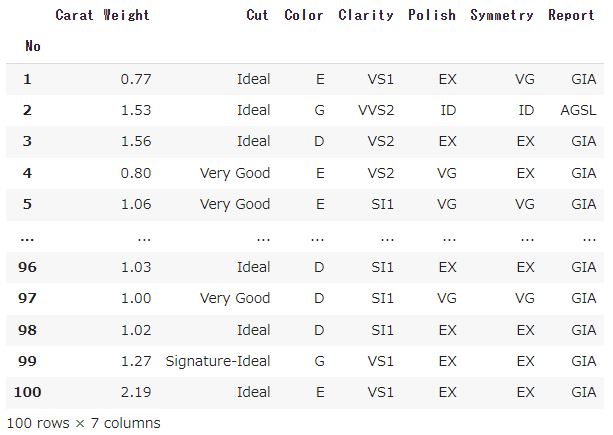
pycaretの練習用として下記にExcelデータを用意しました。
- Sheet1:学習データ(AIにトレーニングさせるためのデータ)・・・5900行
- Sheet2:予測したいデータ・・・100行
- Sheet3:Sheet2の実際のデータ(答え合わせ用データ)・・・100行
学習データと予測したいデータは予測したいcolumn以外一致している必要があります。また、学習データの機械学習は行単位に行われます。以上のことを意識してデータづくりをする必要があります。
今回は練習用のデータとして上記のようなダイヤモンドの価格情報を使用します。ダイヤモンドには詳しくありませんが下記のような情報が入っているようです。
- Carat Weight・・・カラット(重量)
- Cut・・・カット品質
- Color・・・色
- Clarity・・・クラリティ(透明度)
- Polish・・・ポリッシュ(表面研磨の度合い)
- Symmetry・・・シンメトリー(対照的の度合い)
- Report・・・鑑定機関
- Price・・・価格
これらの要素から「Price」を予測するmodelを作っていきます。
また、作ったmodelを使用して下記に用意した予測したいデータの「Price」の値を予測していきたいと思います。
pycaretは使用方法を学ぶために練習用としていくつかデータを提供しています。今回使用するダイヤモンドの価格データもその1つです。
pycaretをインストール後に下記コードにて取得することができます。
|
1 2 |
from pycaret.datasets import get_data data = get_data('diamond') |
「diamond」の部分を変更することで他のデータを取得することもできます。
| 略称 | 内容 |
| diabetes | 糖尿病患者のデータ |
| wine | ワインの品質データ |
| credit | 信用評価データ |
| insurance | 保険データ |
| heart | 心臓病データ |
| boston | ボストンの住宅価格データ |
| diamond | ダイヤモンドの価格データ |
❹pycaretの使用方法
それでは実際にpycaretを使っていきたいと思います。
1.学習データと予測したいデータの読み込み
pandasを使ってDataFrameでど各データを読み込みます。
- data_1:学習データ
- data_2:予測したいデータ
で読込みます。
|
1 2 3 4 5 6 7 8 9 10 |
#Pandasのインポート import pandas as pd #学習データの読み込み data_1 = pd.read_excel('/content/data_diamond.xlsx' , sheet_name = 'Sheet1') data_1 = data_1.set_index('No') #予測したいデータの読み込み data_2 = pd.read_excel('/content/data_diamond.xlsx' , sheet_name = 'Sheet2') data_2 = data_2.set_index('No') |
2.pycaretのインストール
今回はGoogle Colaboratoryを使ってpycaretの使用方法を説明していきたいと思います。まず、下記コードにてpycaretをインストールしていきます。
|
1 2 |
#pycaretのインストール !pip install pycaret |
3.pycaretのインポート
用途によってインポートする内容が変わります。今回は「Price」の値を予測するため回帰「 pycaret.regression」を使います。
回帰以外にも以下のものが用意されています。用途に応じてインポートしましょう。
|
1 2 |
#インポート from pycaret.regression import * |
| 用途 | モジュール名 |
|---|---|
| 分類 | pycaret.classification |
| 回帰 | pycaret.regression |
| クリスタリング | pycaret.clustering |
| 異常検出 | pycaret.anomaly |
| 自然言語処理 | pycaret.nlp |
| アソシエーション分析 | pycaret.arules |
4.学習データの前処理
setup メソッドを使って学習データの前処理を行います。
引数は data = 学習データ と target = 予測する値のあるcolumn名 を指定すれば問題ありません。
今回は引数に
- data = data_1
- target=’Price’
を代入します。
|
1 2 |
#データの前処理 setup(data = data_1 , target = 'Price') |
実行すると学習データの各情報が表示されます。

5.複数のアルゴリズムの比較
compare modelsメソッドを使うことで各アルゴリズムで機械学習を行った場合の成績を確認することができます。
下記コードで直前でsetup メソッドを使って処理を行ったデータで成績を確認できます。
|
1 2 |
#複数のアルゴリズムの比較 compare_models() |
実行すると各アルゴリズムのmodelを使用した際の評価指標の一覧が表示されます。
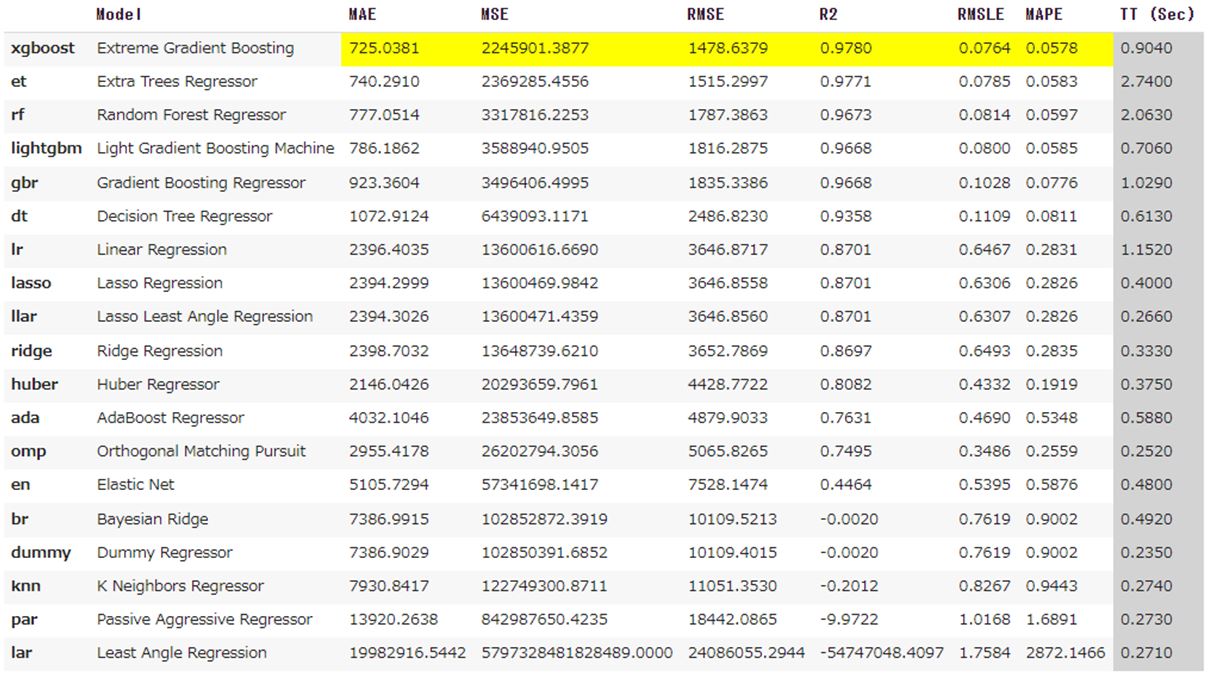
表示される評価指標は下記の通りです。
| 略称 | 評価名 | 評価内容 |
| MAE | 平均絶対誤差 | 予測値と実際の値との差の絶対値の平均。予測誤差の絶対値の平均を評価するため、外れ値の影響を受けにくい。値が小さいほど、予測の精度が高いことを示しす。 |
| MSE | 平均二乗誤差 | 予測値と実際の値との差の2乗の平均。予測誤差の二乗の平均を評価する指標で、小さいほど予測の精度が高いことを示す。MAEよりも大きな値を持つ傾向がある。 |
| RMSE | 平方根平均二乗誤差 | MSEの平方根を取ったもの。実際の値と予測値の差の平均的な大きさを示す。予測誤差の大きさを評価する指標で、値が小さいほど予測の精度が高いことを示す。 |
| R2 | 決定係数 | 実際のデータに対するモデルの説明力を示す。予測変数が目的変数の変動をどれだけ説明できるかを示す。1に近いほど、モデルがデータをよく説明していることを示す。 |
| RMSLE | 平方根平均対数誤差 | 実際の値と予測値の対数を取り、その差の平均の平方根を示す。正確な予測値を重視するタスクで使用する。 |
| MAPE | 平均絶対パーセンテージ誤差 | 予測値と実際の値との差を実際の値の絶対値で割り、その平均を示す。予測誤差の平均の絶対値を評価する指標で、パーセンテージで誤差を表す。 |
| MSLE | 平均二乗対数誤差 | 実際の値と予測値の対数を取り、その差の2乗の平均を示す。対数スケールで評価される指標で、小さな誤差を強調する。 |
| TT | トレーニング時間 | モデルのトレーニングにかかる時間 |
また、比較されるアルゴリズムは下記の通りです。
| 略称 | アルゴリズム名 | アルゴリズム内容 |
| xgboost | Extreme Gradient Boosting | 勾配ブースティング法の一種、多くの決定木モデルを組み合わせて高性能な予測モデルを作成する。 |
| et | Extra Trees Regressor | ランダムフォレストの一種、多数の決定木を組み合わせて予測を行うが、ランダムに分岐を選ぶ。 |
| rf | Random Forest Regressor | 多数の決定木モデルを組み合わせて、バギングとランダム性を用いて予測を行う。 |
| lightgbm | Light Gradient Boosting Machine | 勾配ブースティング法の一種、高速でメモリ効率が良い実装を持つ。 |
| gbr | Gradient Boosting Regressor | 勾配ブースティング法を用いて、アンサンブル学習により予測を行う。 |
| dt | Decision Tree Regressor | 単一の決定木モデルを使用して予測を行う。データの分割ルールにより予測を行う。 |
| lr | Linear Regression | 線形回帰モデルであり、説明変数と目的変数の線形関係をモデル化する。 |
| lasso | Lasso Regression | 線形回帰の一種、L1正則化を用いて説明変数の選択と係数の推定を行う。 |
| llar | Lasso Least Angle Regression | L1正則化を用いた回帰手法で、変数選択を行う。 |
| ridge | Ridge Regression | 線形回帰の一種、L2正則化を用いて係数の推定を行う。 |
| huber | Huber Regressor | ロバスト回帰法の一種、外れ値に対して頑健な予測を行う。 |
| ada | AdaBoost Regressor | アダブースト法を用いてアンサンブル学習を行う。 |
| omp | Orthogonal Matching Pursuit | モデル選択法の一つ、非ゼロの係数を持つ説明変数を選択する。 |
| en | Elastic Net | L1とL2正則化を組み合わせた回帰手法で、変数選択と係数の推定を行う。 |
| br | Bayesian Ridge | ベイズ統計を用いて回帰モデルを構築し、事後分布を推定する。 |
| dummy | Dummy Regressor | ダミーの予測を行うためのモデル、ベースラインとして使用する。 |
| knn | K Neighbors Regressor | 近傍のデータ点を用いて予測を行う非パラメトリックな回帰手法。 |
| par | Passive Aggressive Regressor | オンライン学習のためのアルゴリズムで、重みを適応的に更新する。 |
| lar | Least Angle Regression | 変数選択法で、変数を追加する際に目的変数に最も影響を与える変数を選択する。 |
6.modelの作成
先の項目で表示した評価指標をもとに選んだアルゴリズムでmodelを作成していきます。
model作成時に使用するメソッドは複数あり、順に処理することでmodelの精度をあげていきます。
1.create_modelメソッド
引数で指定したアルゴリズムでmodelを作成します。
今回は一番成績の良かったアルゴリズム「xgboost 」を使いたいと思います。
|
1 2 |
#指定したアルゴリズムでmodelを作成 model=create_model('xgboost') |
実行すると学習データを10分割して公差検証を行い、結果を表示します。
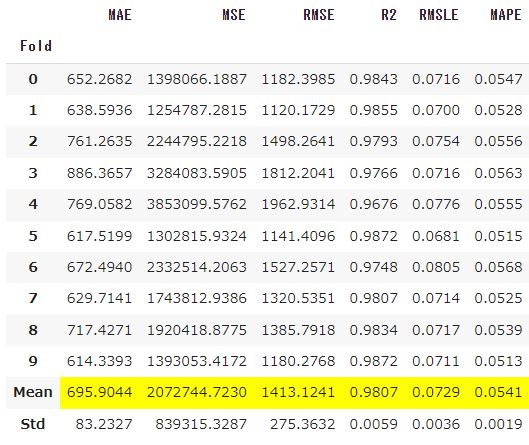
2.tune_modelメソッド
ハイパーパラメータのチューニングを行います。
|
1 2 |
#ハイパーパラメータのチューニング tuned_model=tune_model(model) |
実行するとハイパーパラメータのチューニング後、10分割して公差検証を行い結果を表示します。
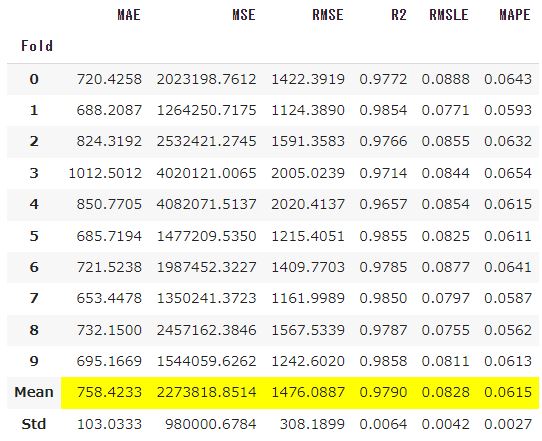
(ハイパーパラメータのチューニング後の結果がもとのmodelより悪かった場合、前のパラメータに戻ります。)
3.evaluate_modelメソッド
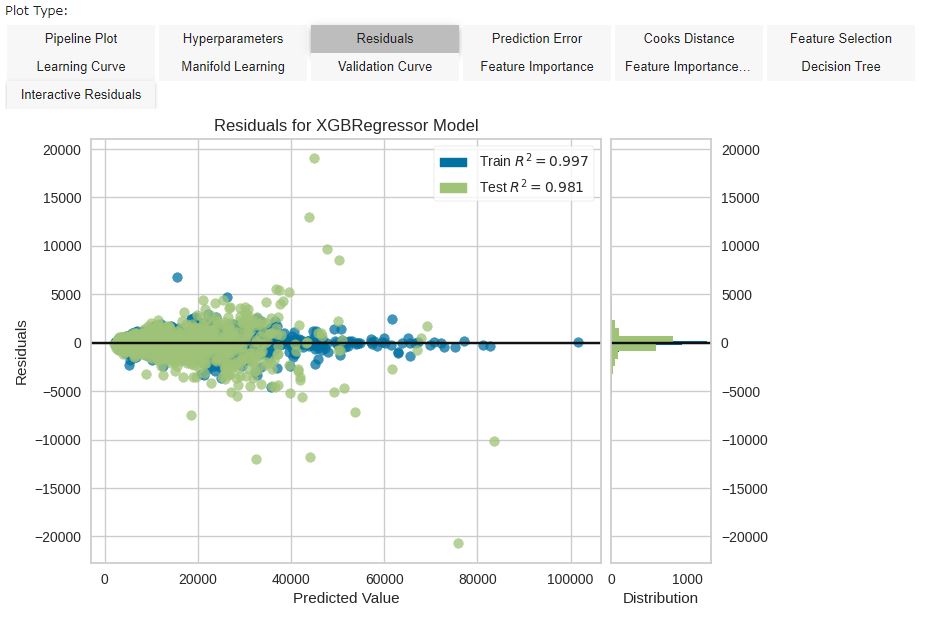
精度を把握するためのグラフを表示します。
|
1 2 |
#modelの精度確認 evaluate_model(tuned_model) |
「Plot Type」にある項目をクリックして選ぶことで様々なグラフや指標を確認できます。
4.finalize_modelメソッド
与えられた全ての学習データを使ってモデルの最終版を作成します。
|
1 2 |
#最終版のmodelを作成 final_model = finalize_model(tuned_model) |
5.save_modelメソッド
作成したmodelを保存します。第1引数に保存するmodel名、第2引数に保存名を含めた保存先のパス を指定します。今回は「finalmodel」という名前で保存します。
|
1 2 |
#最終版のmodel保存 save_model(final_model , '/content/finalmodel') |
実行すると作成した「.pkl」という拡張子でmodelが保存されます。
7.modelの適用
作成したmodelを使って実際に数値の予測をしていきたいと思います。
1.作成したmodelのロード
load_modelメソッドを使用し、作成したmodelを読み込みます。引数部分には使用するmodelのパスを入れます。
|
1 2 |
#使用するmodelの読み込み finalmodel = load_model('/content/finalmodel') |
2.数値の予測
predict_modelメソッドを使って予測したいデータの予測を実行します。引数部分には先ほど読み込んだmodelと予測したいデータを入れます。。
|
1 2 |
#モデルにデータを渡して予測結果を取得 result = predict_model(finalmodel , data = data_2) |
3.予測結果の表示
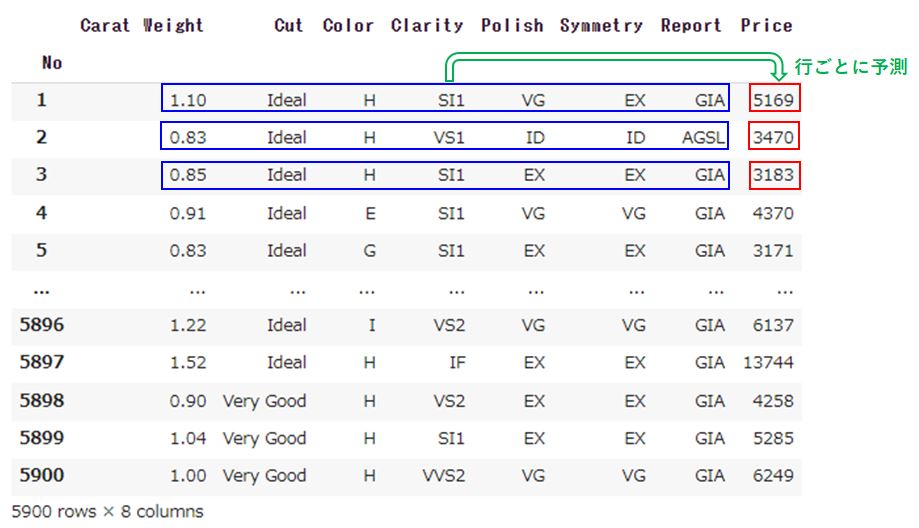
「result」の中に予測結果がDataFrameで格納されます。
|
1 2 |
#予測結果の表示 result |
column名「prediction_label」が予測した値になります。
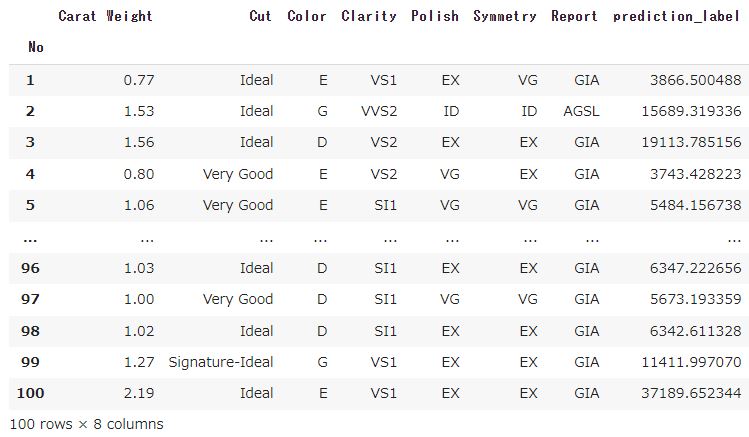
ExcelデータのSheet3に実際の値がありますので答え合わせしてみてください。
❺コードのまとめ
説明は長くなりましたが、数行のコードを書くだけで、複数のアルゴリズムからmodelを作成し、その中から最も成績の良いモデルを選定してくれ、さらにハイパーパラメータのチューニングまでやってくれます。
Pycaretを知ることで機械学習が簡単に扱うことができるようになると思います。
最後に今回使ったコードを下記にまとめます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
#modelの作成方法 #Pandasのインポート import pandas as pd #学習データの読み込み data_1 = pd.read_excel('/content/data_diamond.xlsx' , sheet_name = 'Sheet1') data_1 = data_1.set_index('No') #予測したいデータの読み込み data_2 = pd.read_excel('/content/data_diamond.xlsx' , sheet_name = 'Sheet2') data_2 = data_2.set_index('No') #pycaretのインストール !pip install pycaret #インポート from pycaret.regression import * #データの前処理 setup(data = data_1 , target = 'Price') #複数のアルゴリズムの比較 compare_models() #指定したアルゴリズムでmodelを作成 model=create_model('xgboost') #ハイパーパラメータのチューニング tuned_model=tune_model(model) #modelの精度確認 evaluate_model(tuned_model) #最終版のmodelを作成 final_model = finalize_model(tuned_model) #最終版のmodel保存 save_model(final_model , '/content/finalmodel') ######################################################### #modelの適用方法 #使用するmodelの読み込み finalmodel = load_model('/content/finalmodel') #モデルにデータを渡して予測結果を取得 result = predict_model(finalmodel , data = data_2) #予測結果の表示 result |