Pandasでのファイルを読み込み及び書き出し方法

- PythonへのExcelやCSVファイルの読込み方の理解
- 読込に使うread関数の覚えておくと便利な引数とその使い方
(本記事のコードを作成した開発環境はGoogle Colaboratory Python 3.7.13 となります。)
別記事でPandasでのDataFrameの作り方を紹介しましたが、実際に1からPandasを使ってデータを打ち込んでDataFrameを作ることは少なく、 ExcelのデータやCSVファイル、textファイルを読込んで使うことの方が多いと思います。
本記事ではPandasへファイルを読込んでDataFrameを作る方法と取込時の設定についてまとめました。
今回のコード紹介に使ったサンプルデータは下記の3つになります。
- Google Colaboratoryへのデータのアップロード
- read_〇〇関数の種類
- read_excel関数でExcelデータを読込む
- read_〇〇関数のよく使う引数
- 応用(間にヘッターがあるデータの読込み)
- read_〇〇関数の引数まとめ
- DataFrameの書き出し「to_〇〇」
Google Colaboratoryへのデータのアップロード
Google Colaboratory(以後Colabで統一)は自身のPC内でコードが実行されるわけでなく、Googleが各アカウントごとに用意する仮想マシン上で実行で実行されます。そのため、割り当てられた仮想マシン上に読込みたいデータをアップロードする必要があります。
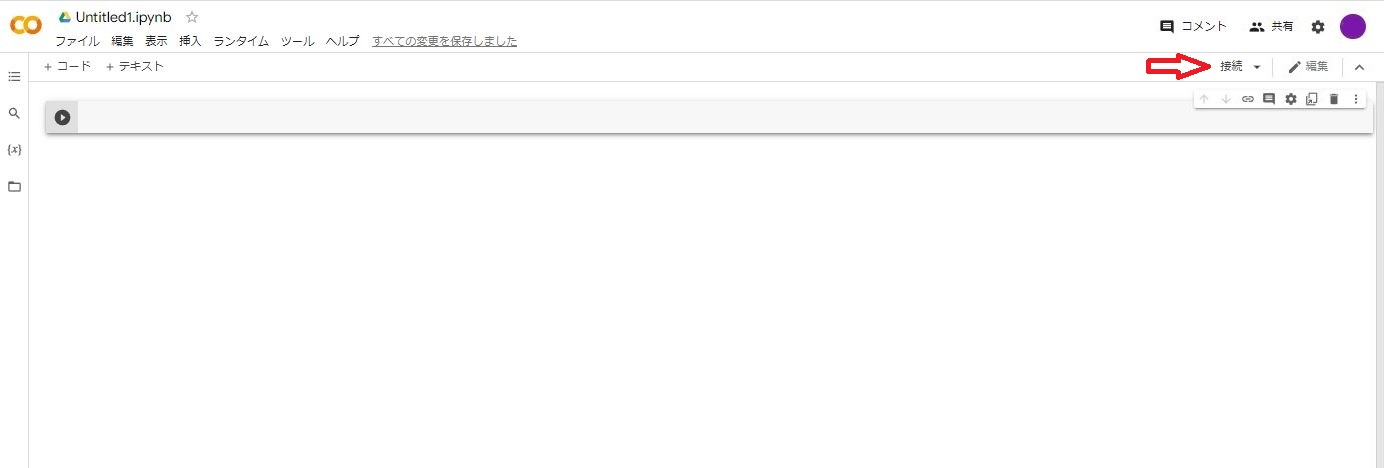
1.Colabの画面を開く
下図の矢印部が「接続」になっていれば仮想マシンに接続されています。「再接続」になっていれば仮想マシンに接続されていないので「再接続」をクリックして「接続」にします。
2.アップロード先を選択
左側のファイルのマークをクリックすると仮想マシンのファイルにアクセスできます。ここで保管場所を選択します。
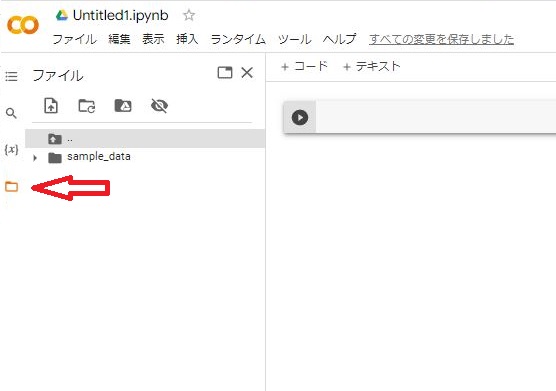
3.データをアップロード
アップロードしたいデータをドラックで保管したい場所に持っていけばアップロードできます。今回は最初から開いているファイルの直下に保管したいと思います。

read_〇〇関数の種類
アップロードしたファイルをPythonで読込むには「read_〇〇」関数を使います。Excelデータを読込むには「read_excel」関数、CSVデータを読込むには「read_csv」関数を使います。いくつか種類があるので下記の表にまとめます。
| No | 読み込むデータフォーマット | 関数 |
| 1 | CSV | read_csv |
| 2 | Fixed-Width Text File | read_fwf |
| 3 | JSON | read_json |
| 4 | HTML | read_html |
| 5 | XML | read_xml |
| 6 | Local clipboard | read_clipboard |
| 7 | MS Excel | read_excel |
| 8 | OpenDocument | read_excel |
| 9 | HDF5 Format | read_hdf |
| 10 | Feather Format | read_feather |
| 11 | Parquet Format | read_parquet |
| 12 | ORC Format | read_orc |
| 13 | Stata | read_stata |
| 14 | SAS | read_sas |
| 15 | SPSS | read_spss |
| 16 | Python Pickle Format | read_pickle |
| 17 | SQL | read_sql |
| 18 | Google BigQuery | read_gbq |
read_excel関数でExcelデータを読込む
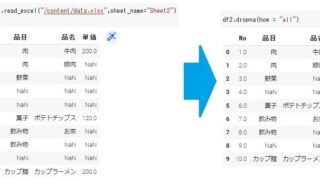
早速アップロードした下記のExcelデータ「data.xlsx」を読込んでみたいと思います。
データの中身は下記のようになります。

まずはPandasをインポートします。
|
1 |
import pandas as pd |
続いてpandasのread_excel関数を使って変数「df1」にアップロードしたExcelデータ「data.xlsx」を代入します。引数となる(” ”)には読み込みたいデータの保管場所(パス)を入れます。

パスは読込みたいデータの上で右クリックすると「パスをコピー」というのが出てくる。クリックして、read_excel関数の引数の部分に(Ctrl+v)等で張り付けます。
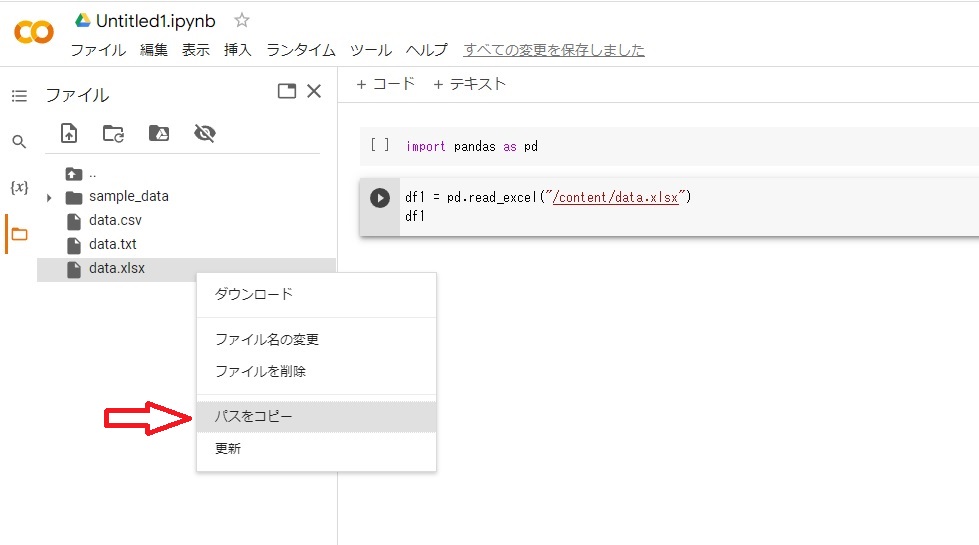
|
1 2 |
df1 = pd.read_excel("/content/data.xlsx") df1 |
すると下記のDataFrameを作ることができると思います。
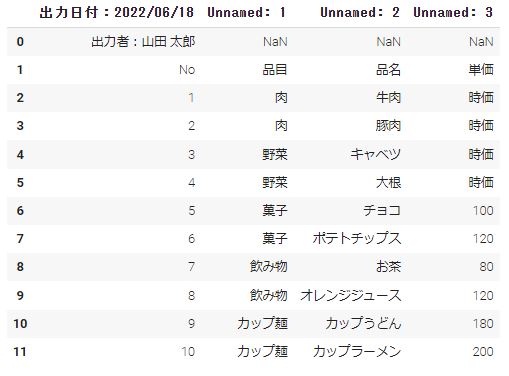
しかし、ヘッター部分の出力日付や出力者も読込まれているため使い勝手悪いDataFrameになっていると思います。
使い勝手の良いDataFrameとして読込むために「read_〇〇」関数にはいくつかの引数があります。次の章でよく使う引数と使い方を紹介します。
read_〇〇関数のよく使う引数
紹介する引数
- header
- usecols
- na_values
- sheet_name
- encoding
- sep
header
データ列の名称が記載されている行を指定する引数 デフォルトはindex番号0行目になります。存在する行数を指定すればその行の値がデータ列の名称として扱われます。存在しない行を設定した場合には1から順に連番が振られる
「data.xlsx」では「header = 2」にすればindex番号で2番目の[No,品目,品名,単価]をcolumns名にすることができます。
|
1 2 |
df1 = pd.read_excel("/content/data.xlsx",header = 2) df1 |
usecols
データを読込むcolumnsを指定することができます。「data.xlsx」のcolumns「No」がいらない場合は、読込みたいcolumns[品目,品名,単価]をusecolsの引数に入れればいいです。
|
1 2 |
df1 = pd.read_excel("/content/data.xlsx",header = 2,usecols = ["品目","品名","単価"]) df1 |
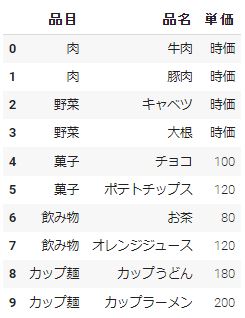
na_values
NaNとして扱う値を指定する引数になります。今回は「data.xlsx」のcolumns「単価」にある「時価」という値をNaNとして読込みたいと思います。
|
1 2 |
df1 = pd.read_excel("/content/data.xlsx",header = 2,na_values = "時価") df1 |

sheet_name
読込むシートを指定します。Excelでは1つのExcelデータに複数のsheetを作ることができます。引数「sheet_name」を使うことでsheetの名前を指定して任意のsheetをDataFrameに読込むことができます。「data.xlsx」のSheet2に「時価」の部分に単価を入れたデータを用意しました。試しに読込んでみてください。
|
1 2 |
df1 = pd.read_excel("/content/data.xlsx",sheet_name = "Sheet2",header = 2) df1 |
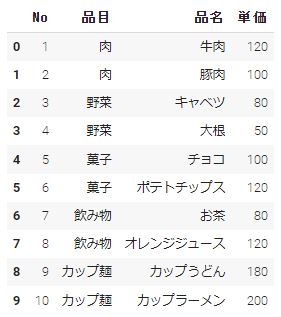
encoding
文字コートを指定する変数になります。 デフォルトではutf-8になります。文字化けしたり読込み時にエラー発生する場合、’shift-jis’や’cp932’を指定することで解決する場合があります。日本語が入っている場合だいたいが文字コードutf-8、shift-jis、cp932を使用しています。
試しにread_csv関数を使って「data.csv」を読込んでみてください。
|
1 2 |
df2 = pd.read_csv("/content/data.csv",header = 2) df2 |
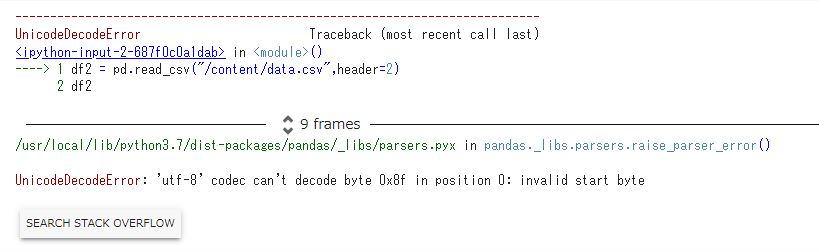
これは読込もうとするデータの文字コードがutf-8ではないために発生するエラーになります。
文字コードをshift-jisにすることで解決できます。
|
1 2 |
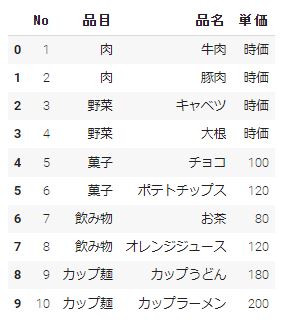
df2 = pd.read_csv("/content/data.csv",header = 2,encoding = "shift-jis") df2 |

sep
区切りの形式を指定するパラメータになります。下にあるようなテキストデータ「data.txt」を読み込んでみてください。
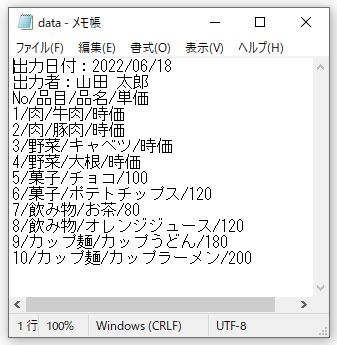
|
1 2 |
df3 = pd.read_csv("/content/data.txt",header = 2) df3 |

テキストデータでは区切る位置を指定しないと、上図のようにくっついて1つの値として読込まれてしまうことがあります。引数sepで区切りとなる文字を指定することできちんとしたDataFrameを作成できます。
|
1 2 |
df3 = pd.read_csv("/content/data.txt",header = 2,sep = "/") df3 |
応用(間にヘッターがあるデータの読み込み)
応用として間にヘッターがあるデータをきれいに読込みむ方法を実践してみたいと思います。読込む元データは下記になります。「data.xlsx」のSheet3に作ってあります。

まずは今まで学んできた通りに読込んでみてください。
|
1 2 |
df4 = pd.read_excel("/content/data.xlsx",header = 2,sheet_name = "Sheet3") df4 |

間にNaNのみの行や出力日付、出力者が入ってしまっていると思います。DataFrameとしては邪魔な行なので削除したいと思います。まず引数commentを使って出力日付と出力者の値をコメント化にします。ともに先頭の文字である「出力」という文字をコメントにします。すると、値がなくなるためNoneという値になると思います。
引数(comment)
- コメント行を識別する記号を指定するパラメータ デフォルトはNone指定した値が初めにある行はコメントとみなしてスルーされる
|
1 2 |
df4 = pd.read_excel("/content/data.xlsx",sheet_name = "Sheet3",comment = "出力") df4 |
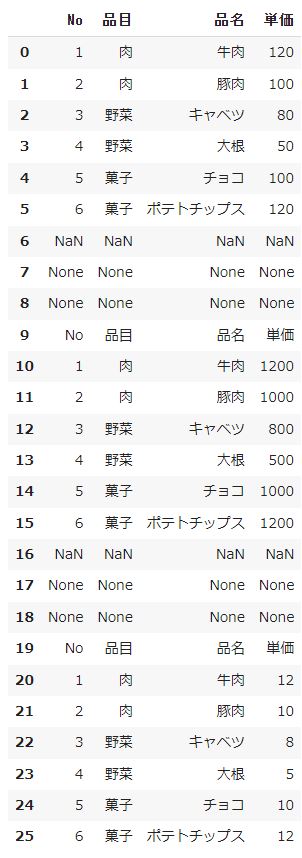
続いてdropna関数を使ってデータのない行を削除します。dropna()は引数を設定しない場合、その行に一つでもデータのないセル(NaN、Noneなど)がある場合、その行を削除する関数になります。また、2と3個目のデータにあったヘッターも削除するためにna_valuesで[No,品目,品名,単価]のどれかをNaNにしておきましょう。
|
1 2 3 |
df4 = pd.read_excel("/content/data.xlsx",sheet_name = "Sheet3",comment = "出力",na_values = "品目") df4 = df4.dropna() df4 |

最後にindex番号が中抜けの状態になっているためreset_index()関数で採番しなおせば完了です。
|
1 2 |
df4 = df4.reset_index() df4 |

read_〇〇関数の引数まとめ
最後にread_〇〇関数の引数の一覧表を書きに示します。赤字は上記で紹介した引数です。
| No | 引数名 | 内容 |
| 1 | dtype | 各列のデータ形式を指定する デフォルトではデータから型を自動判断する |
| 2 | names | 各列のデータ形式を指定する デフォルトではデータから型を自動判断する |
| 3 | sheet_name | 読み込むシートの指定 |
| 4 | skiprows | 各列のデータ形式を指定する デフォルトではデータから型を自動判断する |
| 5 | sep | 区切りの形式を指定する(一般的に使う方) |
| 6 | delimiter | 区切りの形式を指定する |
| 7 | header | データ列の名称が記載されている行を指定する デフォルトは1行目(0) 存在する行数を指定すればその行の値がデータ列の名称として扱われる 存在しない行(例えば-1)を設定した場合には1から順に連番が振られる |
| 8 | index_col | データ行の名称が記載されている列を指定する デフォルトはNone Noneの場合には1から順に自動で行数が振られる |
| 9 | na_values | NaNとして扱う値を指定する デフォルトはNone |
| 10 | false_values | trueとして扱う値を指定する デフォルトはNone |
| 11 | true_values | falseとして扱う値を指定する デフォルトはNone |
| 12 | date_parser | parse_datesで指定した列を結合する際に、関数を指定するためのパラメータ デフォルトはFalse |
| 13 | keep_date_col | parse_datesで指定した列を結合する際に、元の列も残すためのパラメータ デフォルトはFalse |
| 14 | iterator | 読込んだデータをDataFrame型ではなく、Textfilereader型で返す デフォルトはFalse |
| 15 | chunksize | 読み込んだデータをDataFrame型ではなく、Textfilereader型で返す iteratorと異なり、int型を引き数とし、指定した行数で区切って読み込む メモリに乗らないようなサイズの大きなデータを細かく読んでいくときに使う |
| 16 | error_bad_lines | 項目数と一致しない行を見つけた時の処理を指定する デフォルトはTrueで、エラーを返す Falseを指定した場合、その行を飛ばして読み込む |
| 17 | skip_blank_lines | 空欄の行の取り扱いを指定する Trueを指定するとスキップするようになる |
| 18 | warn_bad_lines | 項目数と一致しない行を見つけた時に警告を返す error_bad_linesがFalseであることが必要 |
| 19 | parse_dates | 日付として扱う列を指定する デフォルトはFalse リスト形式で列番号を与えることで、複数の列を日付として処理したり、リスト内でさらにリスト表現することで、日付と時間に分かれている列を結合して日付として認識させることができる 列名を指定するためにはリストでなく辞書形式で渡せばよい |
| 20 | dayfirst | 日付データがDD/MMという形式で入っているデータを読み込む際に設定する デフォルトはFalse(つまり、MM/DD)として読み取る |
| 21 | filepath_or_buffer | 読み込むファイル名を指定するときに使うパラメータ 引数なしで動くので実際に使うことはない |
| 22 | lineterminator | 改行文字を指定する デフォルトでは\rです |
| 23 | skipinitialspace | sep or delimiterで指定した区切り記号の次にあるスペースを無視するかどうかを指定する デフォルトはFalse |
| 24 | compression | ファイル形式を指定する デフォルトはinfer 4種類の値{‘gzip’, ‘bz2’, ‘infer’, None}が設定でき、圧縮ファイルもそのまま読み込める? |
| 25 | quotechar | クォテーションを指定する デフォルトは”(ダブルクォテーション)クォテーションで挟まれた値は1つのデータとみなし、sep or delimiterで指定した区切り記号があっても無視される |
| 26 | escapechar | このパラメータで指定した記号直後のエスケープシーケンスを文字列として扱う |
| 27 | engine | 読み込み処理をCで実施するかPythonで実施するかを指定する Cの方が早くかつ、デフォルトはCなので、使うことはあまりない。 |
| 28 | prefix | headerがNoneのときに、列名の先頭に文字列を付加する デフォルトはNone |
| 29 | keep_default_na | 空欄の要素をNaNとして扱うかを指定する デフォルトはTrue Falseを指定すると下例のように空欄(長さ0の文字列)として扱われる |
| 30 | thousands | 1000ごとの桁区切りの記号を指定する デフォルトはNone この値を指定しておかないと例えば100,000はカンマを区切りとして100と000に分割される |
| 31 | nrows | 読み込むデータの行数を指定する デフォルトはNone(全て) |
| 32 | skipfooter | フッターとみなす行数を指定する フッターとみなしたデータは読み込まない |
| 33 | na_filter | データの空欄等をNaNとして処理するためのパラメータ デフォルトはTrue データ内にこれらの要素がない場合にはFalseを設定することで処理速度を向上させることができる |
| 34 | infer_datetime_format | 時間の扱いにかかわるデータと思われるが、詳細不明 |
| 35 | comment | コメント行を識別する記号を指定する デフォルトはNone 指定した値が初めにある行はコメントとみなしてスルーされる |
| 36 | converters | 変数の型を指定する typesで同じことができそうなので、使う機会は少ないかも |
| 37 | encoding | 文字コートを指定する変数 デフォルトはutf-8 日本語フォントで書かれている文字が文字化けする場合(utf-8で記述されていない場合)、’shift-jis’や’cp932’を指定することで文字化けを防止できることが多い |
| 38 | usecols | データを読み込む列を指定する |
| 39 | decimal | 小数点を識別する記号を指定する デフォルトは「.」 |
| 40 | verbose | デフォルトはFalse。Trueを指定すると変換に要した時間が表示される模様 |
| 41 | squeeze | データを単一列のデータとして読み込む デフォルトはFalse |
| 42 | mangle_dupe_cols | 重複する列がある場合の処理を指定するパラメータ |
| 43 | quoting | クォテーションで囲まれた値の処理方法を指定する デフォルトは0 |
DataFrameの書き出し「to_〇〇」
Pandasで作成、編集したDataFrameをExcelデータやCSVデータの書き出すことができます。データの書き出しには「to_〇〇」関数を使います。先の項目で作成したDataFrame「df4」をExcelデータで書き出してみたいと思います。
Excelデータで書き出す場合は「to_excel」関数を使います。引数となる(” ”)内には書き出した後のデータの保管場所(パス)と書き出した際のファイル名を入れます。

|
1 |
df4.to_excel("/content/df4.xlsx") |
「df4」をExcelデータで書き出すことができました。このデータをダウンロードすれば、自身のPCのExcelで再度編集することができます。
「to_〇〇」関数は他にも種類があり様々なデータ形式で書き出すことができます。下記に書き出せるデータ形式と関数の一覧を作成しました。
| No | 読み込むデータフォーマット | 関数 |
| 1 | CSV | to_csv |
| 2 | JSON | to_json |
| 3 | HTML | to_html |
| 4 | LaTeX | Styler.to_latex |
| 5 | XML | to_xml |
| 6 | Local clipboard | to_clipboard |
| 7 | MS Excel | to_excel |
| 8 | HDF5 Format | to_hdf |
| 9 | Feather Format | to_feather |
| 10 | Parquet Format | to_parquet |
| 11 | Stata | to_stata |
| 12 | Python Pickle Format | to_pickle |
| 13 | SQL | to_sql |
| 14 | Google BigQuery | to_gbq |