PythonがExcelのような使える PandasでのDataFrameの作り方
- Pythonで表(行列データ、DataFrame)が作れるようになる
- DataFrameからの情報の取得方法が身につく
- PythonでExcel業務を自動化する前知識が身につく
(本記事のコードを作成した開発環境はGoogle Colaboratory Python 3.7.13 となります。)
PythonではExcelで扱うような行列データをDataFrame(データフレーム)といい、このDataFrameを扱うのにPandasというライブラリーを使用します。
Pandasを使えば行列データ(DataFrame)の編集、ソート、vlookupのような結合といったExcelでできることはもちろん、統計量の表示なんかも簡単にできたりします。
PythonでExcel業務を自動化するためには必須のライブラリーになります。本記事では、Pandasを使ってのDataFrameの作成、編集、各情報の取得などを行って行きたいと思います。
Pandasを使えば、ExcelデータやCSV、行列のテキストの取り込みもできますが、それは別記事で紹介したいと思います。
- DataFrameについて
- DataFrameの作り方
- index名、column名の変更
- DataFrameから値、行、列を取得する
- DataFrameの値の変更
- 行と列を入れ替える
- DataFrameの情報を取得
DataFrameについて
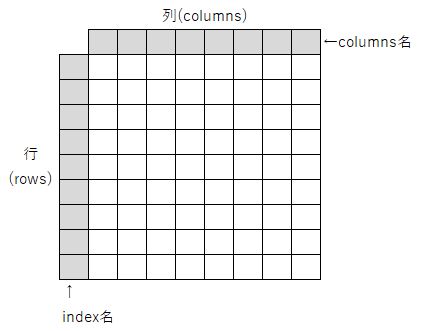
DataFrameでは「行=rows」、「列=columns」といいます。構造としてはExcelと同じなので感覚的に見方がわかると思います。
コードを書くときに「行」を表すのには「rows」となりますが、「行名」を表すときには「index」となります。ここはややこしいと思います。ソートを掛けるときは「index」で指示しますが、表示する行数を指示する時は「rows」を使うイメージです。
DataFrameの作り方
pandasを下記のコードでインポートします。
|
1 |
import pandas as pd |
GoogleColaboratoryを使用していればPandasは最初っから入っているようなので「!pip」でインストールする必要はありません。
クラス「DataFrame」を使ってDataFrameオブジェクトを作成していきます。クラス「DataFrame」の引数は5つあります。
pd.DataFrame( 第1引数 , 第2引数 , 第3引数 , 第4引数 , 第5引数 )
| 引数番号 | 引数名 | 必須/任意 | 備考 |
| 第1引数 | data | 必須 | データとなる値を入れる |
| 第2引数 | index | 任意 | index名を設定 指定がない場合は0から順番にラベリングされる |
| 第3引数 | columns | 任意 | columns名を設定 指定がない場合は0から順番にラベリングされる |
| 第4引数 | dtype | 任意 | データ型を指定(1つのデータ型しか設定できない) 指定しない場合は自動で選ばれる |
| 第5引数 | copy | 任意 | オブジェクトを生成する時にコピーを作るかを決める 初期値はFalseでコピーを作らない設定 |
(今回、第4引数のdtypeと第5引数のcopyは解説を省略します。)
実際にDataFrameを作ってみましょう。
|
1 2 |
df1 = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]]) df1 |
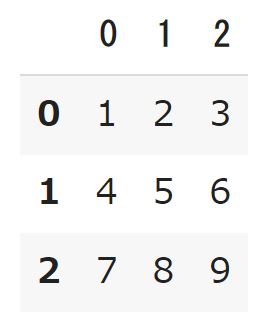
上記のコードでは変数「df1」に作成したDataFrameオブジェクトを代入しています。このように、DataFrameの第1引数のdataの値を入れられればDataFrameオブジェクトを簡単に作ることができます。
続きて第2引数のindexと第3引数のcolumnsを指定してみたいと思います。
|
1 2 3 |
###### 第1引数(data) ###### #### 第2引数(index)### ### 第3引数(columns)### df2 = pd.DataFrame( [[1,2,3],[4,5,6],[7,8,9]] , ["idx1","idx2","idx3"] , ["col1","col2","col3"]) df2 |
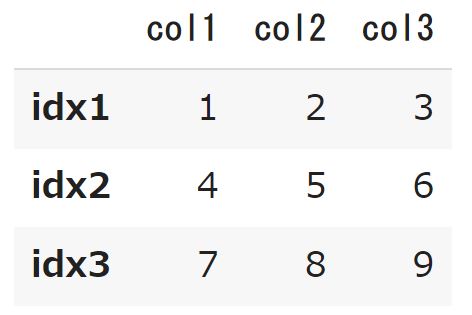
上記のようにすればdataの値、index名、columns名を一緒に設定することができます。
ただ、私はこの書き方ではコードが読みずらいため、
- 引数名 = で指示すれば引数の記入順番が無視できる
- 「 , 」の後に改行できる
ことを利用して下記のように書くようにしています。
|
1 2 3 4 |
df2 = pd.DataFrame(data = [[1,2,3],[4,5,6],[7,8,9]], columns = ["col1","col2","col3"], index = ["idx1","idx2","idx3"]) df2 |
皆さんもコードが見やすくなるように工夫してみましょう。
index名、column名の変更
index名、column名を変える方法は2種類あります。
- index、columnsメソッドを使ってもとある情報に上書きする方法
- renameメソッドを使って変更するよ方法
❶ index、columnsメソッドを使ってDataFrameno情報に上書きする方法
上記で作成した変数「df2」のindex名及びcolumns名を変更してみたいと思います。
|
1 2 3 4 5 6 7 |
#コード1 df2.index = ["行1","行2","行3"] df2 #コード2 df2.columns = ["列1","列2","列3"] df2 |

このように変更したいDataFrameにindexもしくはcolumnsメソッドをつけてlistで指示することで変更することができます。この時、listの要素の数が変更したいDataFrameと一致していないとエラーが発生します。
➋ renameメソッドを使って変更するよ方法
❶と同じように renameメソッドでもindex名及びcolumns名を変更してみたいと思います。
|
1 2 3 4 5 6 7 8 |
#コード1 df2 = df2.rename(index = {"idx1":"行1","idx2":"行2","idx3":"行3"} ) df2 #コード2 df2.rename(columns = {"col1":"列1","col2":"列2","col3":"列3"},inplace = True ) df2 |
index、columnsメソッドでは上書きする形でDataFrameを変更できましたが、renameメソッドでは「df = 」のように違う変数を最初に設定して変更後のDataFrameを再度、変数に代入するか(#コード1)、引数inplaceに「True」を入れなければ(#コード2)変更されません。
しかし、index名及びcolumns名を同時に変更することができます。
|
1 2 3 |
df3 = df2.rename(columns = {"col1":"列1","col2":"列2","col3":"列3"}, index = {"idx1":"行1","idx2":"行2","idx3":"行3"} ) df3 |
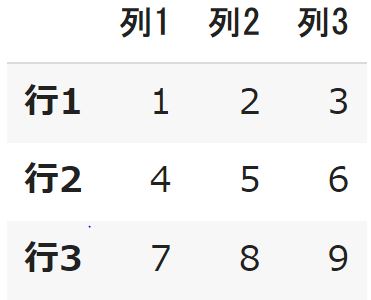
DataFrameから値、行、列を取得する
❶ 値の取得
DataFrameの中から任意の座標の値を取得してみたいと思います。座標の指示方法には2種類あります。
- 1.行名、列名で指示
- 2.行数、列数で指示
行名と列名で指示したいときはlocメソッド、行数と列数で指示したい場合はilocメソッドで行います。試しに先に出したDataFrame「df3」の真ん中の値「5」をlocメソッド、ilocメソッドを使って取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#DataFrame名.loc [ "index名" , "columns名" ] df3.loc[ "行2" , "列2" ] ####出力内容### 5 ############ #DataFrame名.iloc [ index番号 , columns番号 ] df3.iloc[ 1 , 1 ] ####出力内容### 5 ############ |
ilocメソッドでindex番号 , columns番号を指示する時の注意点として数えは「0」から始まることを覚えておく必要があります。一番左上が原点になりますがこの部分の座標は[0,0]になります。そのため、行2、列2の座標が[1,1]になるのです。
➋ 行、列の取得
スライス( : )とlocメソッドもしくはilocメソッドを使うことで、一部の指定した行もしくは列をDataFrameとして取得することができます。下記にlocメソッドを使った例を掲載します。
|
1 2 |
#DataFrame名.loc [ "index名" , "columns名" ] df3.loc[ "行2" , "列2" ] |
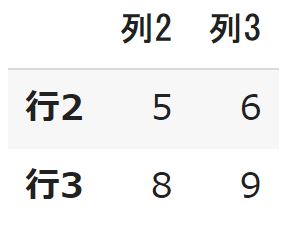
ちなみにindexもしくはcolumnsを指定しないと全行もしくは全列取得されます。
|
1 |
df3.loc [ : , "列2":"列3" ] |
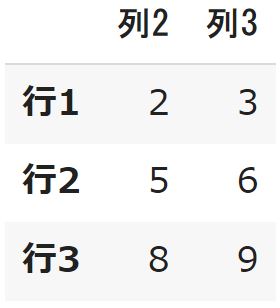
DataFrameの値の変更
locメソッドもしくはilocメソッドを使って、変更箇所を指定し、代入することでDataFrameの値を変更することができます。例として「df3」の真ん中の値「5」をlocメソッドで「50」に変更してみたいと思います。
|
1 2 |
df3.loc["行2","列2"]=50 df3 |
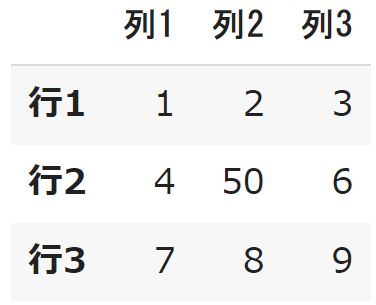
また、スライス( : )と変更内容をlistで指示することで行、列単位で変更することも可能です。
|
1 2 3 4 5 6 7 8 |
#コード1 df3.loc["行3",:]= [70,80,90] df3 #コード2 df3.loc[:,"列1"]= ["東京","埼玉","千葉"] df3 |
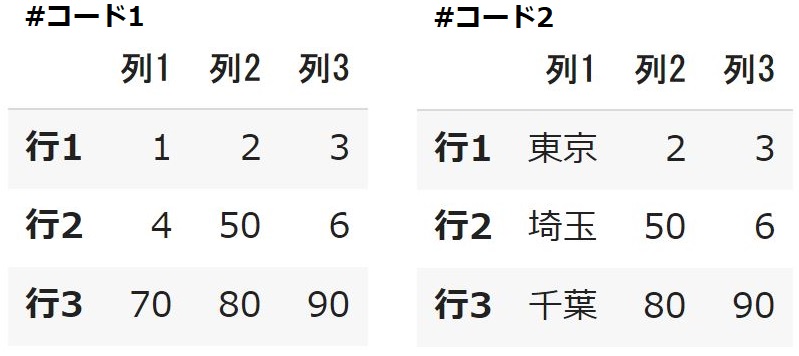
行と列を入れ替える
pandasでは行と列の入れ替えもすごく簡単にできます。入れ替えたいDataFrameの後ろに「T」を付けるだけです。
|
1 |
df3.T |
DataFrameの情報を取得
最後にDataFrame自体の各情報の確認方法をまとめました。情報を取得するDataFrameは下記の「df3」とします。
列数と行数の取得
DataFrame名.shape
|
1 2 3 4 5 |
df3.shape ####出力内容#### (3, 3) ############# |
index名、column名の取得
DataFrame名.index
DataFrame名.columns
index名もしくはcolumns名とそのデータタイプ(dtype)が出力されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
df3.index ###出力内容### Index(['行1', '行2', '行3'], dtype='object') ########### df3.columns ###出力内容### Index(['列1', '列2', '列3'], dtype='object') ########### |
列ごとのデータ型を確認できる
DataFrame名.dtypes
|
1 |
df3.dtypes |

全体的に見たいとき
DataFrame名.info()
|
1 |
df3.info() |

「non-null」というのは欠損値(空欄の箇所)でないデータ数を示しています。
下の例のようにわざと欠損値を作った「df4」というDataFrameをinfoメソッドで確認するとcolumnsのcol3の「non-null」の値が2になっており1つ欠損値「NaNとなっている値」があることがわかります。
|
1 2 3 4 5 6 7 8 9 10 |
#コード1 df4 = pd.DataFrame(data = [[1,3],[4,5,6,],[7,8,9,]], columns = ["col1","col2","col3"], index = ["idx1","idx2","idx3"],) df4 #コード2 df4.info() |