Google Colaboratoryでwebスクレイピング
・会社のPCでwebスクレイピングしたいが環境構築が禁止されている
・開発環境を構築せず、すぐにwebスクレイピングしたい
Pythonを用いてwebスクレイピングを行う場合、く使われている開発環境は「JupyterLab」だと思います。
しかし、「JupyterLab」を使用するのにはパソコンに開発環境のインストールが必要になります。
会社によっては、安易にソフトをインストールすることができない場合もあるかと思います。
また、パソコン内に開発環境を構築していくことはプログラミング初心者にとってハードルが高く、挫折する方も多くいると聞きます。
今回は、このような方におすすめとなる「Google Colaboratory」を用いたwebスクレイピングのさわりの部分をまとめていきたいと思います。
目次
①「Google Colaboratory」とは
②「Colab」と「JupyterLab」との違い
③Colabへのアクセス方法と使い方
④Colabを使ってwebスクレイピング
①「Google Colaboratory」とは
「Google Colaboratory」(以後Colabで統一)とはGoogleが提供しているブラウザを用いたPythonの開発環境になります。
Googleアカウントを持っていれば、ブラウザ「Chrome」、「Firefox」、「Safari」を用いて、ソフトのインストールなどすることなく、すぐにPythonの開発環境を使用することができます。
ウィンドの見た目、使用感は同じくPythonの開発環境である「JupyterLab」と大差ありません。大きな違いとしては
注意点
・Googleアカウントにログインしていないと使用できない
・Chrome、Firefox、Safari以外のブラウザで動作保証はされていない
大きな違いとしては「JupyterLab」は自分のPC内でコードの処理を行いますが、「Colab」はGoogleが各アカウントごとに用意する仮想マシン上で実行することです。詳細はこの後説明します。
②「Colab」と「JupyterLab」との違い
| 比較内容 | Colab | JupyterLab |
| 1.開発環境の構築 | 不要 | 要 |
| 2.コードの保管場所 | Googleドライブ | 自分のPC内 |
| 3.コードの実行場所 | Googleの仮想マシン上 | 自分のPC内 |
| 4.PCスペックとの関係 | 無 | 有 |
| 5.自分のPC内のファイル操作 | 不可 | 可 |
| 6.ダウンロードしたデータの保管場所 | Colab内 | 自分のPC内 |
1.開発環境の構築
JupyterLabは開発環境のインストールする必要がありますが、Colabはインストールなどの開発環境の構築などは一切不要です。必要なのは指定のブラウザを使える環境とGoogleアカウントのみです。
2.コードの保管場所
JupyterLabは自分のPC内でコードの作成と保管を行います。それに対し、「Colab」はGoogleドライブに保管されます。
3.コードの実行場所
JupyterLabは自分のPC内でコードの実行を行います。それに対し、「Colab」はGoogleが各アカウントごとに用意する仮想マシン上で実行します。
4.PCスペックとの関係
JupyterLabは自分のPC内でコードの実行するため、処理の速さはPCのスペックに依存します。それに対し、「Colab」はGoogleが用意する仮想マシン上でコードの実行を行うため、自分のPCのスペックは関係ありません。ブラウザが動けば十分です。
5.自分のPC内のファイル操作
しかし、Colabは仮想マシン上でコードの実行を行うため、自分のPC内にあるフォルダやファイルの操作はできません。リモートでGoogleが用意したPCにアクセスして、そのPCでコードの実行を行っている感じです。
6.ダウンロードしたデータの保管場所
また、同様の理由でColabはスクレイピング時に取得したダウンロードデータなどは自身のPCに保存されません。Googleが用意する仮想マシン上に保存されるため、別途自分のPCにダウンロードする必要があります。また、Colaby上にダウンロードしたデータは一定時間で削除されてします。
・仮想マシンへの接続は最大12 時間、それを過ぎると仮想マシンから切断される
=Colab上にあるデータは消える
・ブラウザを閉じてから一定時間たつと想マシンから切断される(90分?)
=Colab上にあるデータは消える
③Colabへのアクセス方法と使い方
1.Colabのページへアクセス
2.新規ノートブックの作成
3.ファイル名の変更
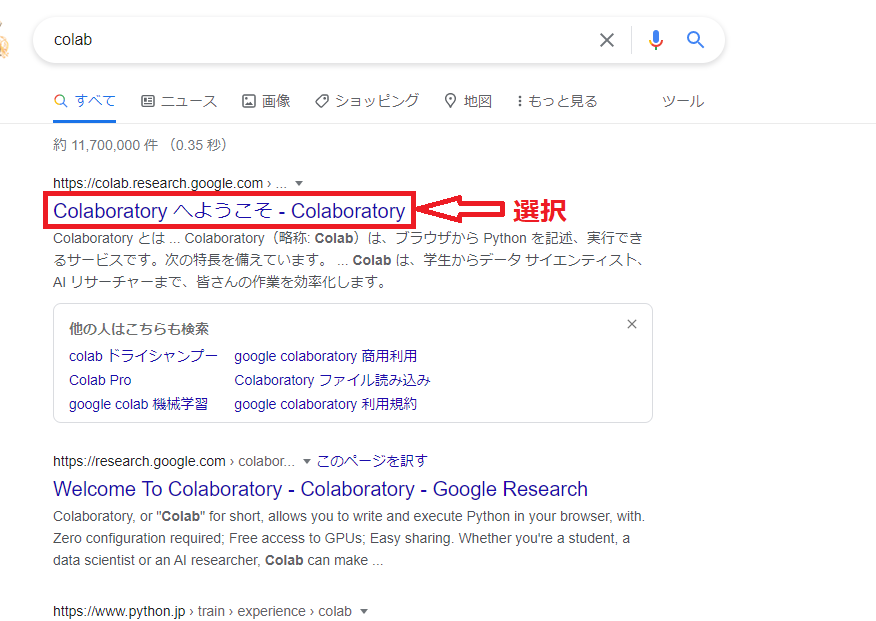
1.Colabのページへアクセス
指定されているブラウザ(Chrome、Firefox、Safari)で「Colab」と検索することでColabのページへアクセスすることができます。ページへアクセスする際に指定されているブラウザ以外だと、ブラウザの画面上に警告がでます。また、Googleアカウントにログインしてない場合、ログインを求められます。
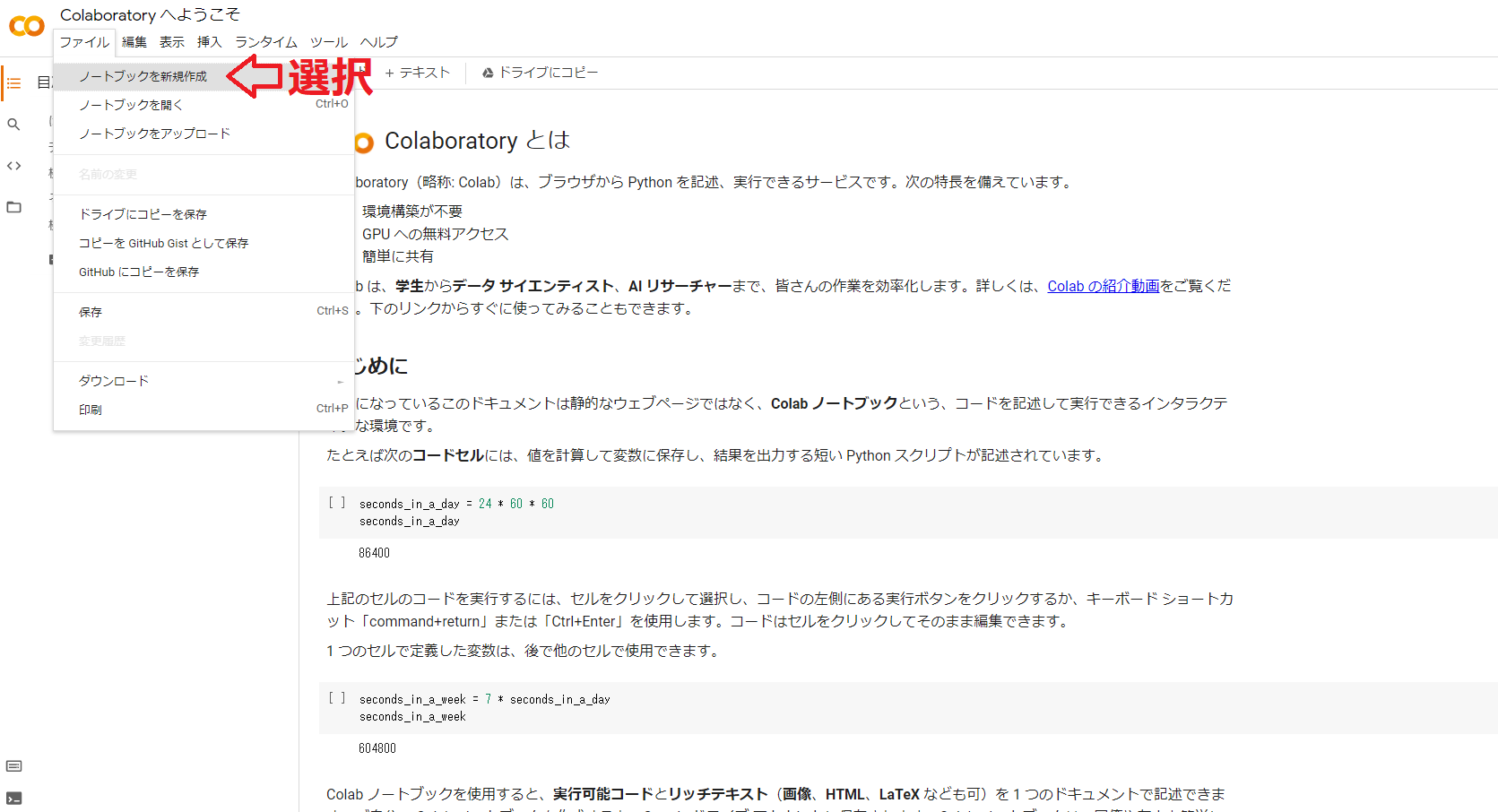
2.新規ノートブックの作成
無事Colabのページへアクセスできると下のような画面が開きます。「ファイル→ノートブックを新規作成」を選択することで新規ノートブックを作成できます。
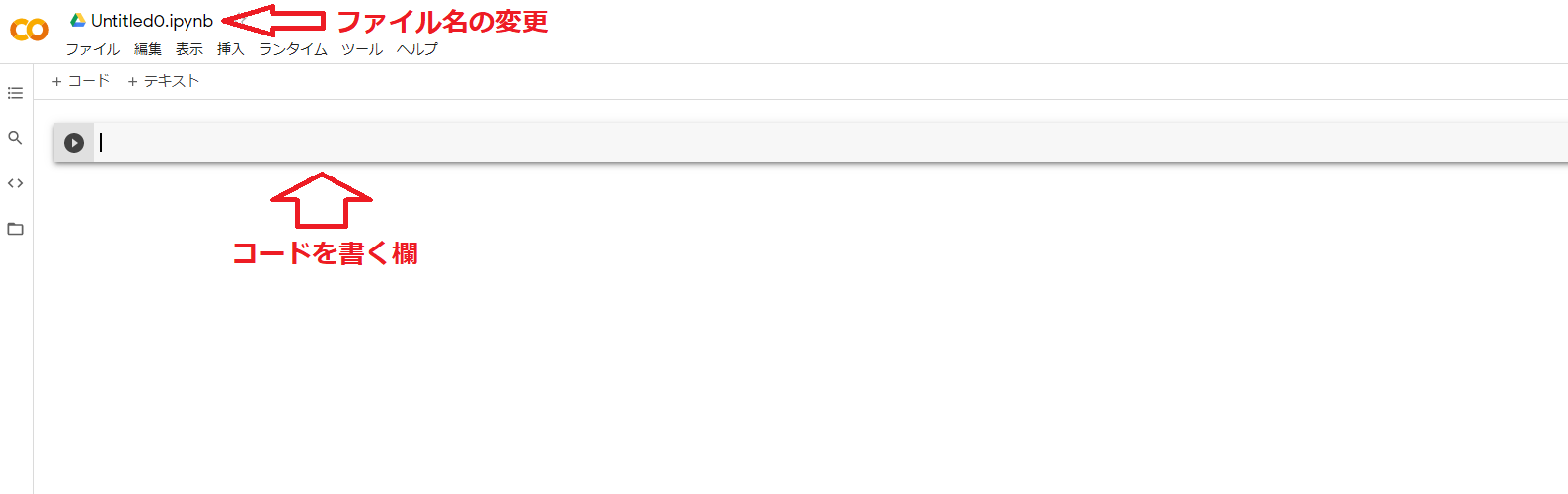
3.ファイル名の変更
右上にある「Untitled0.ipynd」の部分をクリックすると編集できるようになります。この部分がファイル名になりますのでお好みの名前を付けてください。コードを実行した際に自動でGoogleドライブのマイドライブ内に保存されます。
④Colabを使ってwebスクレイピング
実際にwebスクレイピングを行ってみたいと思います。今回は試しに本ブログの「ブログ名」を取ってきたいと思います。
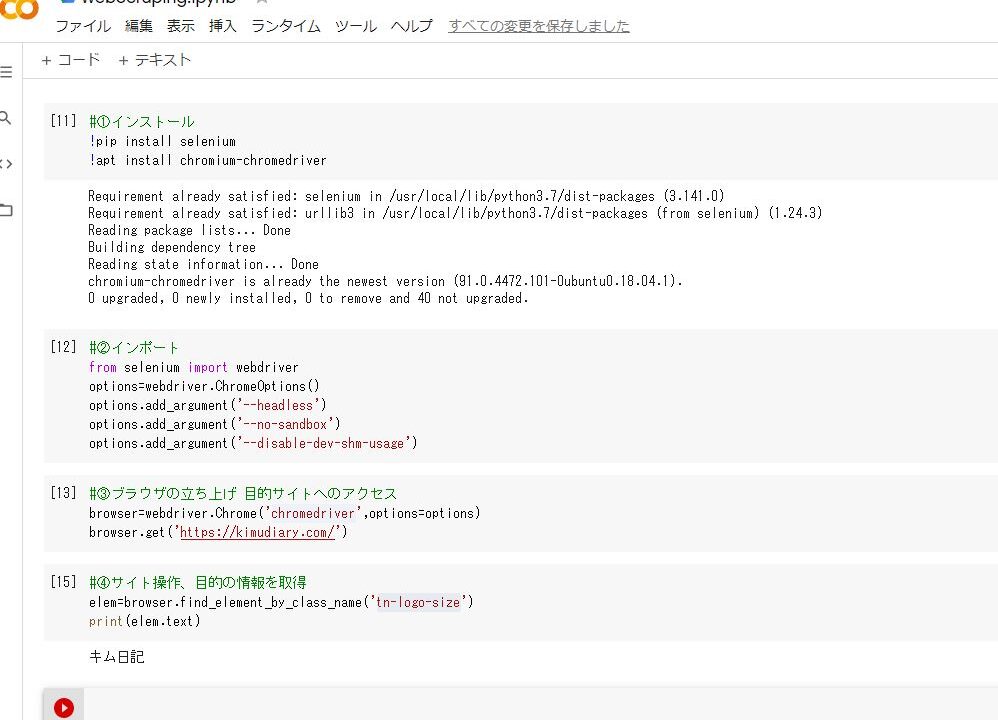
1.インストール
2.インポートと設定
3.ブラウザの立ち上げ 目的サイトへのアクセス
4.サイト操作、目的の情報を取得
5.コードのまとめ
1.インストール
インストール情報はColaboratory上に保存に保存されるため一定時間がたつと消えてします。一番最初のコード実行時には読み込む必要性があります。
|
1 2 3 |
#ドライバーのインストール !apt install chromium-chromedriver #chromeドライバのインストール !pip install selenium #seleniumをインストール ブラウザー操作に使用 |
2.インポートと設定
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#インポートと設定 #webドライバのインポート from selenium import webdriver #element指定に使用 from selenium.webdriver.common.by import By #インポートしたwebドライバの設定 options=webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') #処理待ち時間の指示に使用 import time |
3.ブラウザの立ち上げ 目的サイトへのアクセス
|
1 2 3 4 5 6 7 8 |
#ブラウザの立ち上げ、目的サイトへのアクセス #ブラウザの立ち上げ browser=webdriver.Chrome('chromedriver',options=options) time.sleep(3) #目的サイトへのアクセス(キム日記にアクセス) browser.get('https://kimudiary.com/') |
青字の部分のURLを変えることで目的サイトの変更ができます。
4.目的の情報を取得
|
1 2 3 4 5 6 7 |
#目的の情報を取得 #エレメントの指定 elem=browser.find_element(by=By.XPATH, value='//*[@id="site-info"]/span/a') #エレメントをテキストとして表示 print(elem.text) |
目的の情報を得るためには、サイト内にある取得したい情報をHTML(サイトを構成しているプログラム)から探し出し、そのXPathをwebスクレイピングのプログラムに組み込まなければなりません。
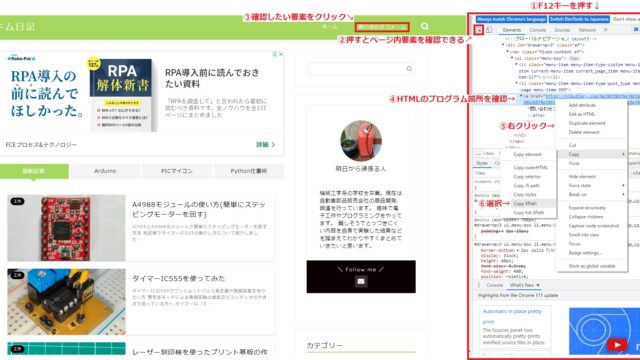
上記のプログラムの4行目がそれにあたり、「//*[@id=”site-info”]/span/a」がXPathになります。XPathの出し方をしたの画像にて解説します。
①キーボードのF12キーを押すと右にサイトを構成するHTMLが出る。
②ページ内の要素を確認できるようになる。
③確認したい要素をクリック
④要素のHTML構成箇所を確認
⑤右クリック
⑥「Copy」から「Copy XPath」をクリック
これで任意の部分のXPathを取得できる
ほかの解説サイトを参考に自身が行いたいことをコードに書いていけばできると思います。
5.ブラウザーのシャットダウン
|
1 2 |
#ブラウザーのシャットダウン browser.quit() |
6.コードのまとめ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
#①ドライバーのインストール !apt install chromium-chromedriver #chromeドライバのインストール !pip install selenium #seleniumをインストール ブラウザー操作に使用 #②インポートと設定 #webドライバのインポート from selenium import webdriver #element指定に使用 from selenium.webdriver.common.by import By #インポートしたwebドライバの設定 options=webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') #処理待ち時間の指示に使用 import time #③ブラウザの立ち上げ、目的サイトへのアクセス #ブラウザの立ち上げ browser=webdriver.Chrome('chromedriver',options=options) time.sleep(3) #目的サイトへのアクセス(キム日記にアクセス) browser.get('https://kimudiary.com/') #④目的の情報を取得 #エレメントの指定 elem=browser.find_element(by=By.XPATH, value='//*[@id="site-info"]/span/a') #エレメントをテキストとして表示 print(elem.text) #⑤ブラウザーのシャットダウン browser.quit() |