Pythonでwebスクレイピング(要素の取得と操作方法まとめ)
Seleniumでwebスクレイピングする際に知っておきたいメソッドとそれらの使い方を紹介します。
皆さんがインターネットを使っている際に行っている動作は基本的に
- マウスの(左)クリック
- キーボード入力
- プルダウンの選択
- ブラウザバック
と問意外に少ないかと思います。
Pythonライブラリ「Selenium」を使えばこれらの作業を自動化することができます。
本記事では、Seleniumでこれらの操作をする際に使用するメソッドの紹介と使い方についてまとめてみました。
また、実際に
- 文字の取り込み(サイト上の文書の取り込み)
- 画像収集(サイト上の画像の取り込み)
といった作業をSeleniumで行う際のコードについても紹介しております。
Webスクレイピングによる情報の収集自体には違法性がないとされておりますが、 著作権を侵害する使い方や、過度なアクセスによるサーバへの負荷といった問題をはらんでおります。Webサイト側の利用規約の確認や過度なアクセスにならないように考慮したシステム作りをし、自己責任のもとでWebスクレイピングを活用していきましょう。
- 必要なドライバ、ライブラリのインストールとインポート
- 要素の取得
- クリック
- 文字入力
- ブラウザバック
- 文字の取り込み
- 画像の取り込み
- プルダウンの選択
- ブラウザを閉じる
❶必要なドライバ、ライブラリのインストールとインポート
・Google Colaboratoryの場合のドライバ、ライブラリのインストールとインポート及びブラウザの起動
Google Colaboratoryでのwebスクレイピングについては、以前に書いた別記事で基本的なやり方を解説しております。そのため、今回はコードのみの紹介とします。
詳しく知りたい方は別記事「Google Colaboratoryでwebスクレイピング」をご覧ください。
下記コードでドライバ、モジュールのインストールおよび使用するモジュール等のインポート が完了し、ヘッドレスモードでGoogleChoromeが起動している状態になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
%%shell ######################################################################## ### ### ### Ubuntuのバージョンが18から20に上がりましたことによるエラー回避 ### ### non snap版のchromiumをダウンロードするコード ### ### ### ######################################################################## cat > /etc/apt/sources.list.d/debian.list <<'EOF' deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster.gpg] http://deb.debian.org/debian buster main deb [arch=amd64 signed-by=/usr/share/keyrings/debian-buster-updates.gpg] http://deb.debian.org/debian buster-updates main deb [arch=amd64 signed-by=/usr/share/keyrings/debian-security-buster.gpg] http://deb.debian.org/debian-security buster/updates main EOF apt-key adv --keyserver keyserver.ubuntu.com --recv-keys DCC9EFBF77E11517 apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 648ACFD622F3D138 apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 112695A0E562B32A apt-key export 77E11517 | gpg --dearmour -o /usr/share/keyrings/debian-buster.gpg apt-key export 22F3D138 | gpg --dearmour -o /usr/share/keyrings/debian-buster-updates.gpg apt-key export E562B32A | gpg --dearmour -o /usr/share/keyrings/debian-security-buster.gpg cat > /etc/apt/preferences.d/chromium.pref << 'EOF' Package: * Pin: release a=eoan Pin-Priority: 500 Package: * Pin: origin "deb.debian.org" Pin-Priority: 300 Package: chromium* Pin: origin "deb.debian.org" Pin-Priority: 700 EOF apt-get update apt-get install chromium chromium-driver #seleniumをインストール !pip install selenium #インポートと設定 #webドライバのインポート from selenium import webdriver #element指定に使用 from selenium.webdriver.common.by import By #画像URLからバイナリ読み込むのに使用 import requests #インポートしたwebドライバの設定 options=webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--disable-dev-shm-usage') #処理待ち時間の指示に使用 import time #GoogleChoromeを起動 browser=webdriver.Chrome('chromedriver',options=options) time.sleep(3) |
・JupyterLabでのドライバ、モジュールのインストールとインポート
JupyterLabでwebスクレイピングするためには
- seleniumのインストール
- chromedriverのダウンロード
が必要になります。
seleniumのインストールについては、JupyterLabで下記コードを執行すれば終わります。
|
1 2 |
#seleniumのインストール !pip install selenium |
chromedriverのダウンロードについては、ブラウザで「chromedriver.exe」と検索すれば ダウンロードサイトを見つけることができます。
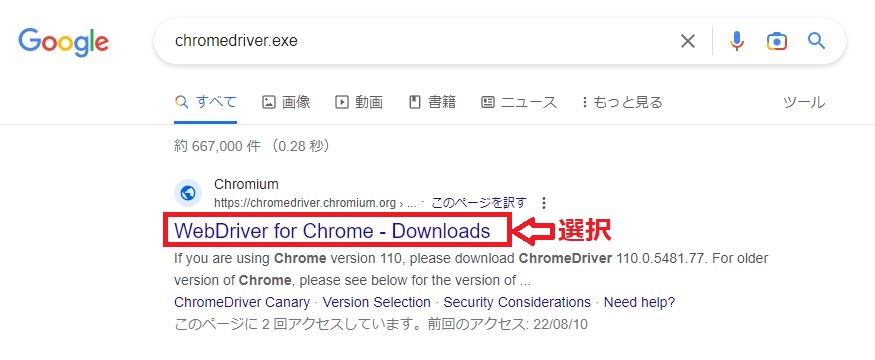
ダウンロードサイトを見るといろいろなバージョンのchromedriverをダウンロードすることができます。今使っているGoogle Chromeのバージョンにあったドライバーをダウンロードしましょう。
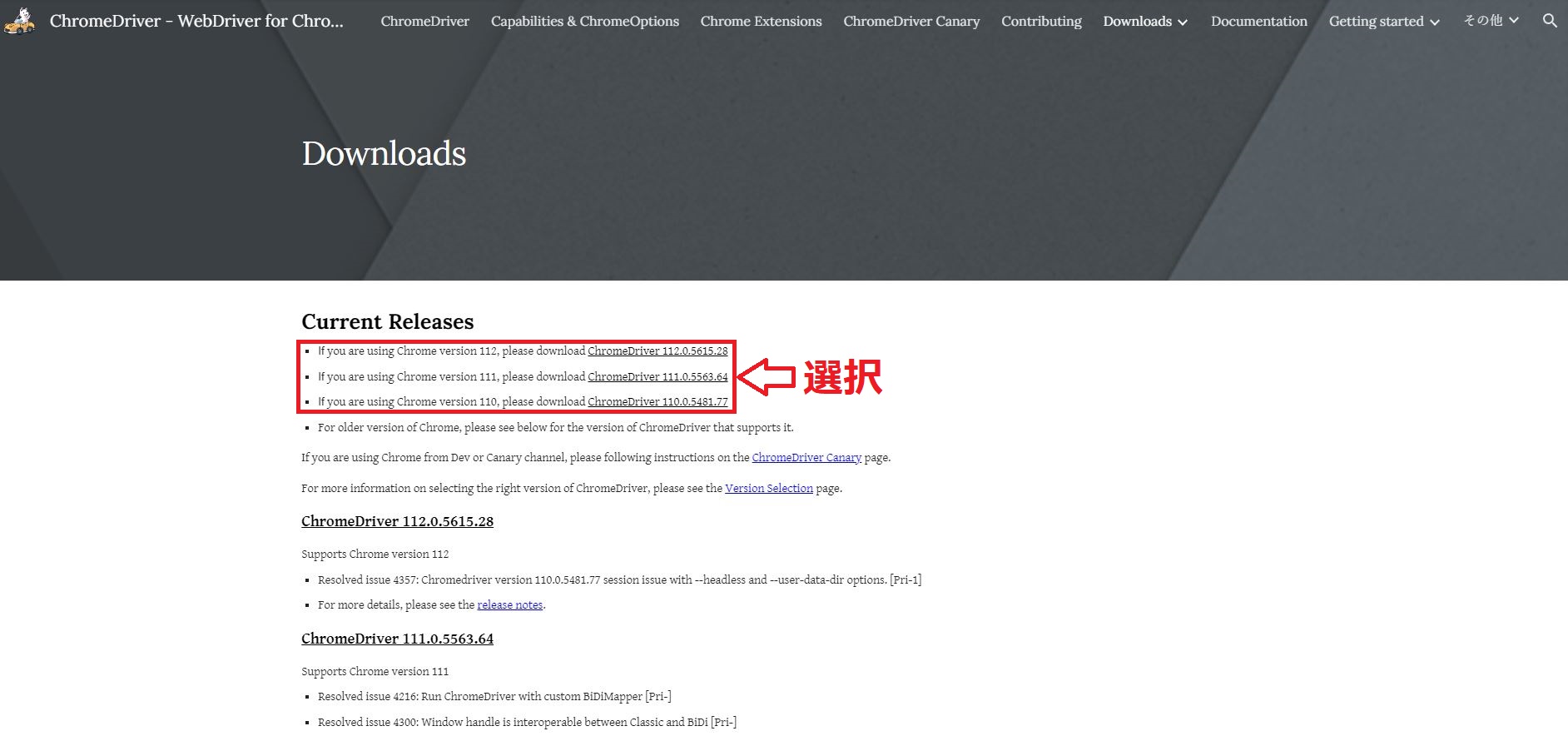
seleniumのインストールとchromedriverのダウンロードが終わりましたらモジュール等のインポートを行い、GoogleChoromeを起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#インポート #webドライバのインポート from selenium import webdriver #element指定に使用 from selenium.webdriver.common.by import By #画像URLからバイナリ読み込むのに使用 import requests #処理待ち時間の指示に使用 import time #GoogleChoromeを起動 browser=webdriver.Chrome(executable_path='D:\デスクトップ\chromedriver.exe') time.sleep(3) |
・目的とするサイトへ遷移
ブラウザを開くまではGoogle ColaboratoryとJupyterLabでコードが違いましたがここから先は同一になります。
下記コードで目的サイトへ遷移することができます。今回は本ブログ(キム日記)にアクセスしてみましょう。
|
1 2 3 |
#ブラウザの立ち上げ、目的サイトへのアクセス browser.get('https://kimudiary.com/') time.sleep(3) |
➋要素の取得
サイト上で何かアクション(クリックや文字入力)をする際、どの部分にアクションをしていくのか定義する必要があります。その場所の情報を入手することを本記事では 「要素の取得」と表しています。
今回はXpathから要素を取得していきたいと思います。
目的の要素を取得するためには、サイト内にある取得したい情報をHTML(サイトを構成しているプログラム) から探し出し、そのXPathをwebスクレイピングのプログラムに組み込まなければなりません。
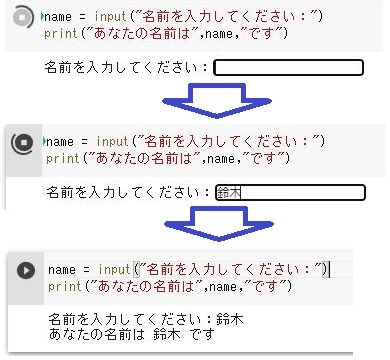
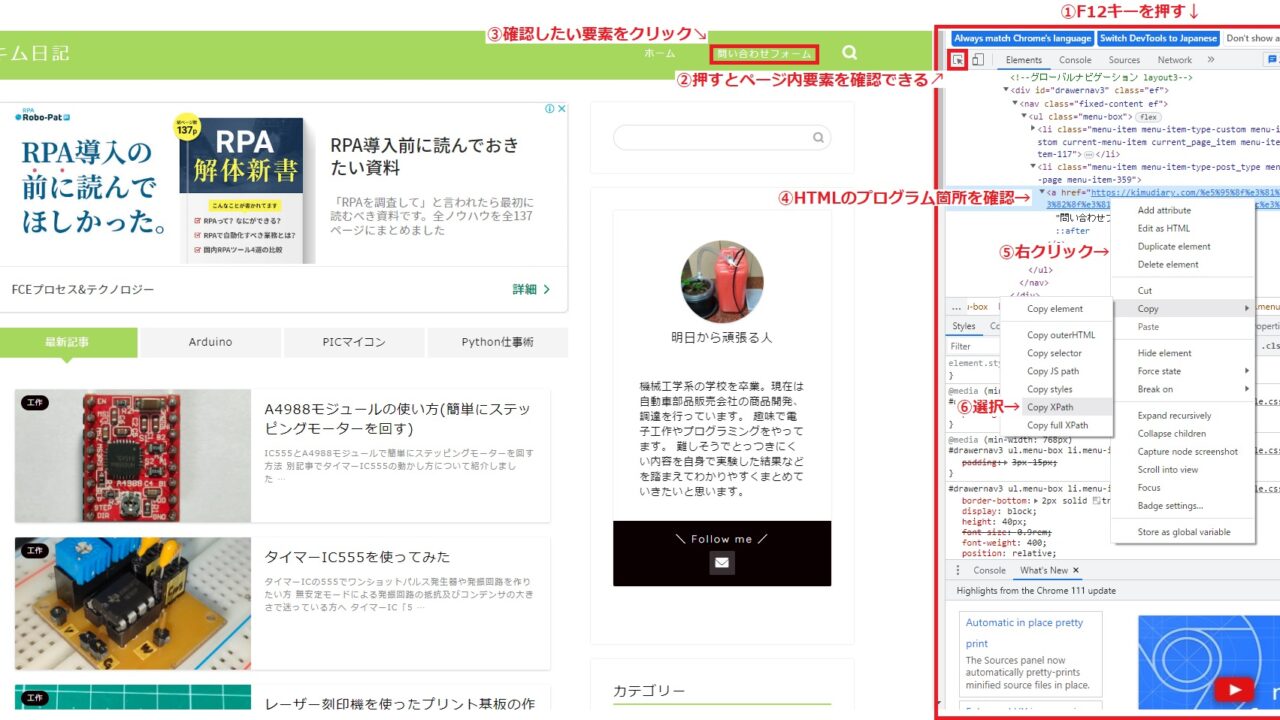
XPathの出し方をしたの画像にて解説します。

- キーボードのF12キーを押すと右にサイトを構成するHTMLが出る。
- クリックするとページ内の要素を確認できるようになる。
- 確認したい要素をクリック
- 要素のHTML構成箇所を確認
- 右クリック
- 「Copy」から「Copy XPath」をクリック
これで任意の部分のXPathを取得できます。
find_elementメソッドの引数「value」に任意のXpathを入れれば要素を取得することができます。
任意の変数名=browser.find_element(by=By.XPATH, value=’取得したい要素のXpath’)
下記コードで変数「inquiry_form」に当ブログの「問い合わせフォーム」アイコンの要素を格納することができます。
|
1 |
inquiry_form=browser.find_element(by=By.XPATH, value='//*[@id="drawernav3"]/nav/ul/li[2]/a') |
❸クリック
取得した要素をクリックするにはclickメソッドを使用します。
クリックしたい要素.click()
下記コードで当ブログの問い合わせフォームのアイコンをクリックして 問い合わせフォームのページに遷移することができます。
|
1 2 3 4 5 |
#要素「問い合わせフォーム」を取得 inquiry_form=browser.find_element(by=By.XPATH, value='//*[@id="drawernav3"]/nav/ul/li[2]/a') #「問い合わせフォーム」をクリック inquiry_form.click() time.sleep(3) |
❹文字入力
文字の入力を行うにはsend keysメソッドを使います。
入力したい箇所の要素.send_keys(‘入力内容’)
下記コードでは問い合わせフォームの氏名の欄に「明日から頑張る人」と入力できます。もともと入力されている内容があると望んだ動きをしない可能性があるためclearメソッド で要素内の入力内容を全消ししてから、文字入力するコードを実行すると良いでしょう。
|
1 2 3 4 5 6 7 |
#要素「氏名」を取得 name=browser.find_element(by=By.XPATH, value='//*[@id="wpcf7-f338-p340-o1"]/form/p[1]/label/span/input') #要素「氏名」内の入力をクリアにする name.clear() #要素「氏名」内に入力 name.send_keys('明日から頑張る人') time.sleep(3) |
❺ブラウザバック
ブラウザバックするにはbackメソッドを使います。
下記コードでブラウザバックすることができます。
|
1 2 |
#ブラウザバック browser.back() |
❻文字の取り込み
テキストの要素をfind elementメソッドで取得した場合、要素内には取得したテキスト情報が入っています。しかし、普通に要素内のテキストをprint関数で表示しようとすると望んだ表示がされないかと思います。

そういう時は、後ろに「.text」を入れることで要素内のテキストのみを抽出することができます。
|
1 2 3 4 |
#要素「サイト名」を取得 site_name=browser.find_element(by=By.XPATH, value='//*[@id="site-info"]/span/a') #要素「サイト名」のテキスト内容を表示 print(site_name.text) |
❼画像の取り込み
画像の取得についてはRequestsモジュールも使っていきます。 プログラムの流れとしては
- ①画像の要素を取得
- ②画像のURLを取得
- ③画像URLからバイナリ読み込む
- ④バイナリデータを画像データで書き出す
となります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#画像の要素を取得 Image=browser.find_element(by=By.XPATH, value='//*[@id="main-contents"]/div[2]/div/div[1]/article[1]/a/div/div[1]/img') #画像のURLを取得 img_url = Image.get_attribute("src") #画像URLからバイナリ読み込む response = requests.get(img_url) image = response.content #バイナリデータをjpg形式で書き出す with open("保存先URL.jpg", mode="wb")as wf: wf.write(image) |
❽プルダウンの選択
プルダウンから選択する場合にはSelectモジュールのselect byメソッドを使用します。
select byメソッドには3種類ありますが、その中で今回は
- 選択したい値でを指定するメソッド(select by valueメソッド)
- 選択したい値のインデックス番号でを指定するメソッド(select by indexメソッド)
を紹介します。
|
1 2 3 4 5 6 |
#SelectモジュールのSelectをインポート from selenium.webdriver.support.select import Select #Select byメソッドの使い方 Select(入力したい箇所の要素).select_by_value(選択したい値) Select(入力したい箇所の要素).select_by_index(選択したい値の番号(0から始まる)) |
❾ブラウザを閉じる
ブラウザを閉じるにはquitメソッドを使います。
|
1 2 |
#ブラウザを閉じる browser.quit() |